Spring ai 1.1 智能体开发全实战笔记 基础学习AGENT+RAG+FC+MCP
代码仓库地址: https://gitee.com/cold-abyss_admin/jx-ai-agent
环境:
- Java 21
- dashscope 2.22.11
- spring-ai-alibaba-starter 1.0.0-M6.1
前言
博主本身实在之前qwen3的时候就简单的写过一个简易版智能体 本地部署过一个小参数deepseek学习了一下 智能体的其他知识 如 RAG 上下文记忆 等知识
今天心血来潮 正好qwen3.5 给了 很多的免费token 就想着去跑个hello world 之后呢在按照自己的想法拓展一下 就当是学习了 但是发现现在的qwen文档 (可能是我没找到 ) 存在一定的问题 比如qwen3.5 全员多模态 调用的api 出现了 变化 文档里提到了一嘴 但是示例代码却没什么变化 导致出现报错
进过半小时的探索 决定留下一个快速从qwen3转到 3.5 需要避免的几个小坑 仅代表个人观点奥
1. 确定好版本
我习惯和qwen的网页端双排了 有不懂的就搜一下 一下数据来自qwen-wen
dashscope-sdk 的版本
依赖版本:必须使用 dashscope-sdk-java 2.21.10 或更高版本(支持多模态)
如果你想要免费试用这次的多模态模型 那么请一定记住需要
2 示例代码的问题
在你的项目一切就绪之后 准备跑示例代码出现问题 会出现报错
这里以dashscope为例
可以从今天的官方文档中 看出啊 即使是3.5模型点进去的示例代码 仍然是以qwen3-plus 为主的 Generation.call的实例
这里如果你使用这套示例 一定会报错的 因为

在这个提示错误连接中 你获得了一些线索 其实如果你是一个搜打撤老手 这个时候已经可以去人工智能那里根据这个类 , 这里其实文档有给我们提示 我们也可以直接在导航栏找到图像与视频理解
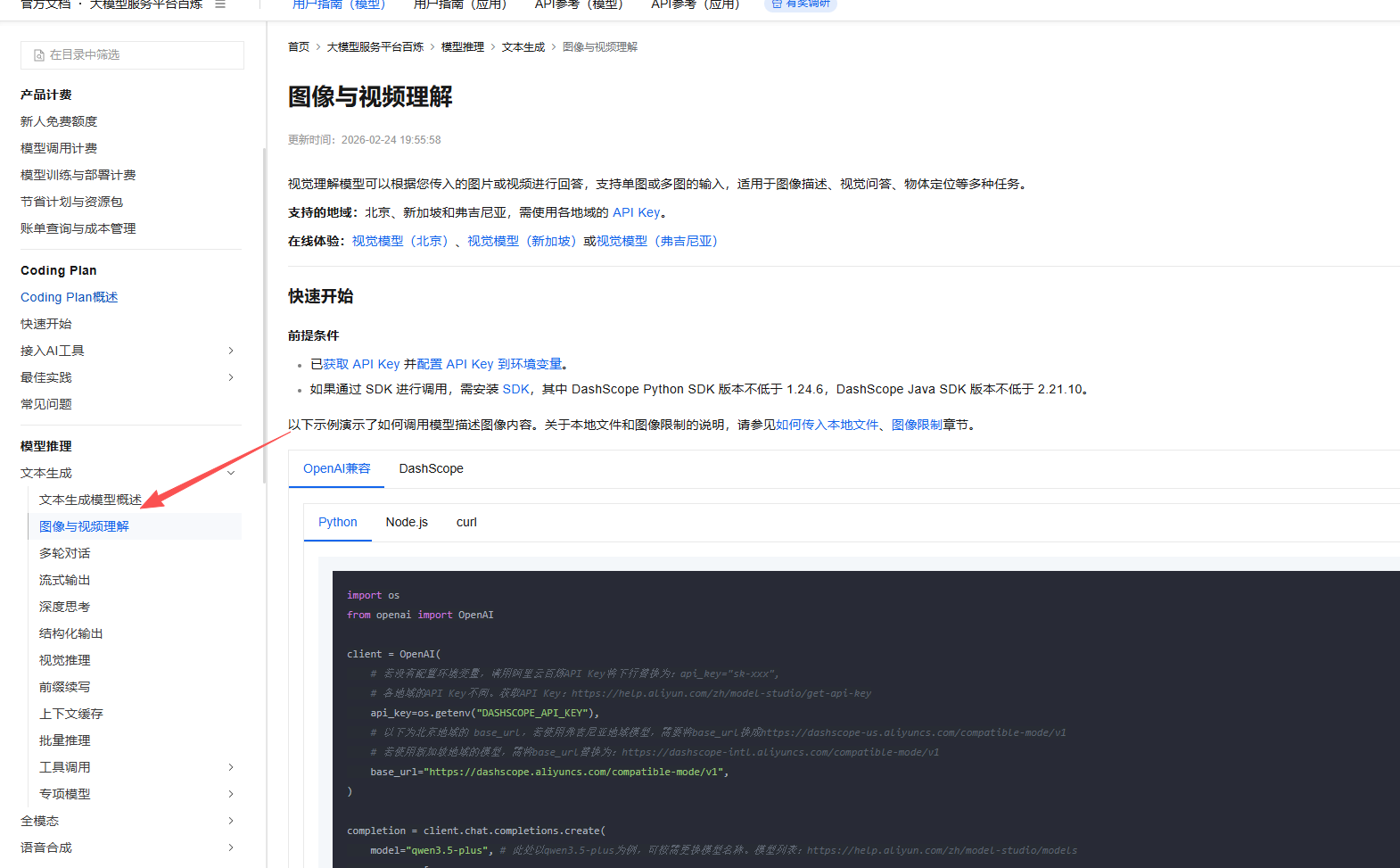
你就可以得到多模态的调用示例了 , 其实文档完善还有待提高 但是好在还是有些线索的
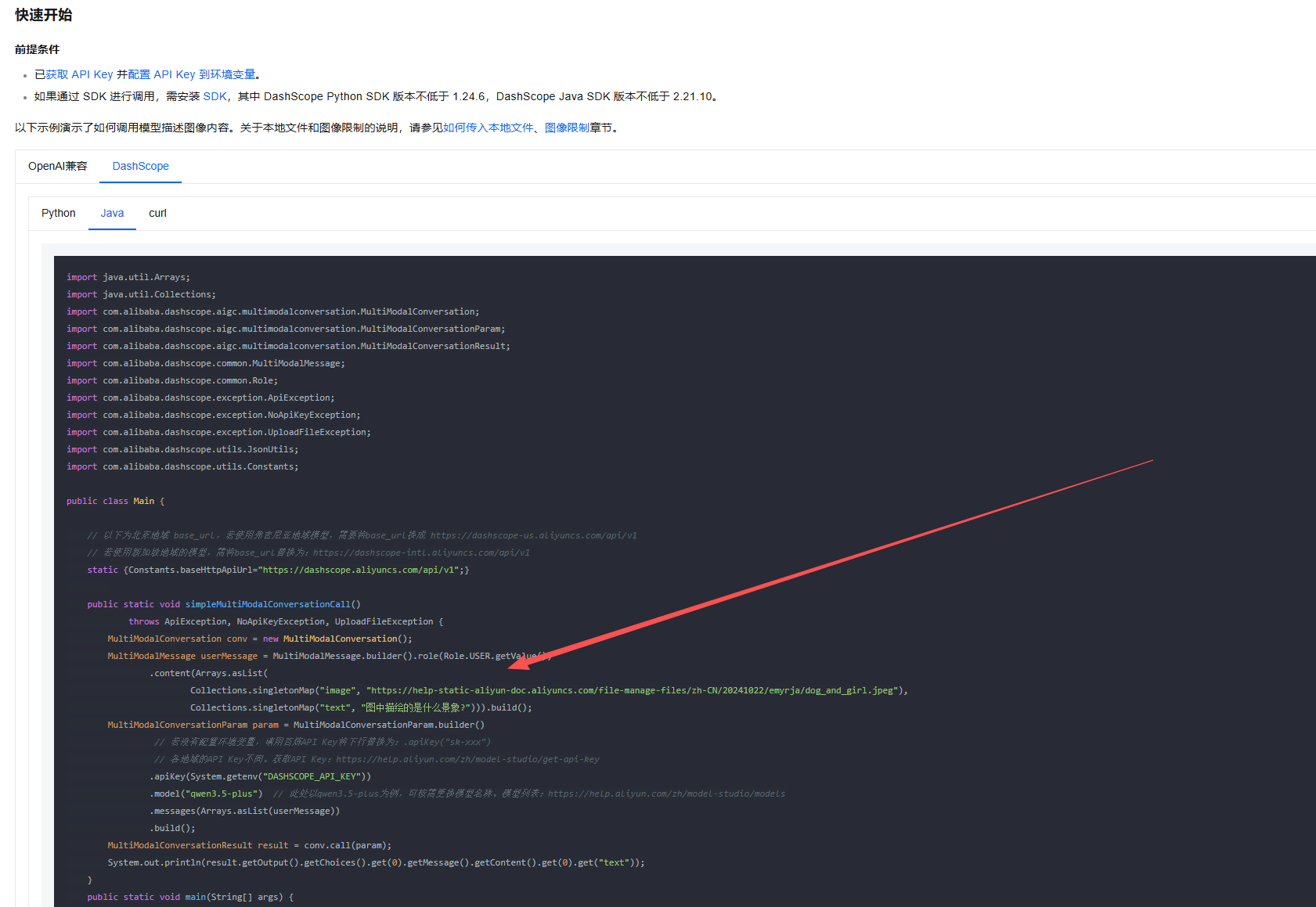
这里就是使用多模态的对话方案 可以看到请求的信息从普通的生成式message变成了
一个含有Map的列表 以
key作为分类包含
text和image
提示词
提示词工程是 使用AI 智能体 或者一些ai文字输入ai工具必备的技术
复习一下文本生成模型的信息概念
文本生成模型的输入为提示词(Prompt),它由一个或多个消息(Message)对象构成。每条消息由角色(Role)和内容(Content)组成,具体为:
- 系统消息(System Message):设定模型扮演的角色或遵循的指令。若不指定,默认为"You are a helpful assistant"。
- 用户消息(User Message):用户向模型提出的问题或输入的指令。
- 助手消息(Assistant Message):模型的回复内容。
我们往往需要精确 多轮的提示词来让ai帮助我们完成需求
这里给开发 ai智能体的部分提示词做一个分类
[核心] 基于角色分类
如基于 角色分类:
- 专业工程师
- 心理咨询师
- 算命先生
基于功能分类
-
指令性(最常见): 明确告知AI需要执行的任务 和各个步骤
系统提示词: 你是一个经验丰富的Java教师 擅长解决初学者的问题
用户: 请给我演示一下 在java中的集合如何使用
-
对话形 (最常见): 模拟自然对话 以问答的形式和AI交互
比如 你觉得人工智能会代替 程序员吗
-
创意性提示词 : 引导 ai 进行模型交互 创意内容生成 比如 图片 诗词 广告文案
写一个关于火星撞地球的科幻故事
-
角色扮演提示词 : 让大模型扮演特定的角色 来进行回答
你是爱迪生 你能和我说说你是如何发明灯泡的吗
-
少量样本的学习提示词 : 基于一些案例 让大模型理解并且按照案例输出
比如 原句 我是一个大宝剑
帮我改写这段文字 更加有欧洲王者风范
基于复杂度分类
-
简单提示词 : 一句话 没有任何复杂背景和条件的问题
-
复杂提示词: 包含一些步骤 或者 相关指令的提示词
-
链式提示词(比较高效率): 将一系列连续相互依赖的提示词 发送给大模型 循序渐进分好步骤
比如
- 生成一个番茄炒蛋攻略
- 根据不同的地域 进行口味创新
- 如何让蛋保持滑嫩口感不散
-
模版提示词: 包含一些可以替换的变量的提示词 可以动态的更换提示词
比如 你是一个 职业 ${厨师}
提示词优化
高质量的提示词可以显著的提升AI输出的质量
这里推荐区 openAi和 spring提供的提示词 多参考
网上还有提示词库
- 文本对话 authropic
基础优化
- 明确确定角色定位和需要做到的任务 帮助模型理解背景和期望
- 提供详细的说明和具体的实例,比如指定多个条件 和规定示例格式等
- 使用结构化思维 引导大模型
- 明确输出格式要求 (核心)
如: 写一片关于气候变化的科普文章 要求:
- 使用适合高中生的语言
- 包含七个小标题 每个标题下三段文字
- 总字数控制在800字
进阶技巧
-
CoT 思维链提示法
比如 先帮我计算出这段公式的用法
然后帮我带入各个参数 计算出结果
根据带入结果 验算
-
少样本学习
通过几个输入和输出的实例 让大模型理解我们的需求模式和期望输出
-
分步骤指导
将复杂的任务 拆分成可管理的步骤 需要确保模型完成每一个环节
-
让AI 自我评估并修正 让ai自己做验算
-
知识检索和引用 : 引导大模型指出明确的信息来源 作为参考避免出错
-
让AI 作为多个不同的立场和角度来分析问题 提供不同见解的理解
-
多模态思维 : 比如文字 + 图片+音频 多方面的去作参考和实例 去得到结果
提示词调试
-
逐步的去完善和修改相同问题的提示词 比如 逐渐缩小专业范围 如
- ai的影响
- ai在某领域的影响
- ai在这个领域的某个工作的影响
-
边界测试 通过极限情况来测试模型 找到优化空间和上限
-
提示词模板化 : 将条件相同的步骤拆分成模板 来实现相同步骤不同内容的达成效果的提示词
TOKEN
大模型处理文本的计算单位 不同模型对于 token 的划分是不一样的
这很重要 这涉及到对于预算的节约
- 英文 一个token大约相当于 4个字符 约等于 0.7个单词
- 中文 一个汉字 约等于 1~2个token
- 空格和标点符号 也会被计算到token中
- 特殊表情符号 可能需要更多的token去表示
输入和输出的收费价格 可能是不一样的, 推荐是列为可量化内容的表格 来展示
成本优化技巧
系统提示词 用户提示词等都是会消耗成本的 所以优化需要从多个角度来
精简 系统提示词
移除掉一些没必要的表述 只保留最核心的指令
如 你是一个有耐心 非常专业的程序员
修改为 你是程序员
定期清理对话历史
在智能体交互中 对话历史会作为上下文不断的累积 如果控制不好
在长对话中 会非常的消耗token 所以要定期的去维护和清理
使用向量检索代替直接输入
对于需要大量参考文档 不要直接将整个文档作为提示词 而是利用向量数据库或检索技术 比如 RAG 来代替一些段落
结构化代替自然语言
使用表格 列表等结构化的格式 代替过长的描述
需求 MVP 最小可行产品策略
MVP 最小可行产品策略是指先开发包含 核心功能 的基础版本产品快速推向市场,以最小成本验证产品假设和用户需求。通过收集真实用户反馈进行迭代优化,避免开发无人使用的功能,降低资源浪费和开发风险。
功能设计
根据需求,我们将实现一个具有多轮对话能力的 AI 恋爱大师应用。整体方案设计将围绕 2 个核心展开:
- 系统提示词的设计
- 多轮对话的实现
系统提示词设计
系统提示词需要精简 但是不能太过简约, 最简单的作法就是 你是谁 你需要做什么 这样可以做到简单的工作 但是效果不会很理想 我们可以思考一下 一个真正的专家需要怎么去做
- 需要我来帮助你什么 哪方面的问题
- 通过询问 来完善背景和一些解决问题需要的必要条件
- 通过循序渐进的多轮对话 来解决用户的问题
智能体对话基础开发
依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.38</version>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.37</version>
</dependency>
<dependency>
<groupId>com.github.xiaoymin</groupId>
<artifactId>knife4j-openapi3-jakarta-spring-boot-starter</artifactId>
<version>4.4.0</version>
</dependency>
<!-- Spring AI Alibaba Agent Framework -->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
<version>1.1.0.0</version>
</dependency>
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-agent-framework</artifactId>
<version>1.1.2.0</version>
</dependency>
<!-- Spring AI Document Reader for Markdown -->
<!-- Source: https://mvnrepository.com/artifact/org.springframework.ai/spring-ai-markdown-document-reader -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-markdown-document-reader</artifactId>
<version>1.1.3</version>
<scope>compile</scope>
</dependency>
<!--用于RAG 写入提示词增强 Source: https://mvnrepository.com/artifact/org.springframework.ai/spring-ai-advisors-vector-store -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
<version>1.1.3</version>
<scope>compile</scope>
</dependency>
<!-- 支持结构化输出-->
<dependency>
<groupId>com.github.victools</groupId>
<artifactId>jsonschema-generator</artifactId>
<version>4.38.0</version>
</dependency>
<!-- 用来高性能序列化 Source: https://mvnrepository.com/artifact/com.esotericsoftware/kryo -->
<dependency>
<groupId>com.esotericsoftware</groupId>
<artifactId>kryo</artifactId>
<version>5.6.2</version>
</dependency>
</dependencies>
Spring 配置
这里我们 将api-key 作为系统环境变量 来调用 确保本地学习的安全性
spring:
application:
name: jx-ai-agent
ai:
dashscope:
chat:
options:
model: qwen3-max-2026-01-23
api-key: ${AI_DASHSCOPE_API_KEY}
server:
port: 8123
servlet:
context-path: /api
# springdoc-openapi项目配置
springdoc:
swagger-ui:
path: /swagger-ui.html
tags-sorter: alpha
operations-sorter: alpha
api-docs:
path: /v3/api-docs
group-configs:
- group: "default"
paths-to-match: "/**"
packages-to-scan: com.hyc.jxaiagent.controller
# knife4j的增强配置,不需要增强可以不配
knife4j:
enable: true
setting:
language: zh_cn
智能体设置
- 系统提示词
- 大模型参数配置
- 窗口大小
- 日志打印
- 对话记忆
- 调用大模型
这里我们使用的是最新版本的 spring ai 1.1 注入会话记忆语法上出现了一些改变
PS: 未来穿越回来的小冷 这里最好设置上 maxtoken 不然你的token会如雪花般消散
@Component
@Slf4j
public class LoveApp {
private final ChatClient chatClient;
// 系统提示词
private static final String SYSTEM_PROMPT = "你在之后的对话中可以自称小恋,扮演深耕恋爱心理领域的专家。开场向用户表明身份,告知用户可倾诉恋爱难题。" +
"围绕单身、恋爱、已婚三种状态提问:单身状态询问社交圈拓展及追求心仪对象的困扰;" +
"恋爱状态询问沟通、习惯差异引发的矛盾;已婚状态询问家庭责任与亲属关系处理的问题。" +
"引导用户详述事情经过、对方反应及自身想法,以便给出专属解决方案。";
public LoveApp(ChatModel dashScopeChatModel) {
MessageWindowChatMemory chatMemory = MessageWindowChatMemory.builder().maxMessages(6).build();
chatClient = ChatClient.builder(dashScopeChatModel)
.defaultSystem(SYSTEM_PROMPT)
.defaultAdvisors(
//自定义拦截器
new JxLoveAppLoggerAdvisor(),
// 在需要的时候开启 new ReReadingAdvisor(),
MessageChatMemoryAdvisor.builder(chatMemory).build()
)
.defaultOptions(ChatOptions.builder()
.maxTokens(512)
.build())
.build();
}
/**
* AI 基础的对话操作 配置会话记忆
*
* @author 冷环渊
* date: 2026/3/16 下午10:27
*/
public String doChat(String message, String chatId) {
ChatResponse chatResponse = chatClient
.prompt()
.user(message)
// chatid用于分离会话和设置记忆的上下文数量 控制篇幅和成本
.advisors(spec -> spec.param(ChatMemory.CONVERSATION_ID, chatId))
.call()
.chatResponse();
return chatResponse.getResult().getOutput().getText();
}
}
测试 基础对话
@Test
void doChat() {
String chatId = UUID.randomUUID().toString();
String message = "您好 我是小冷 ";
String answer = loveApp.doChat(message, chatId);
Assertions.assertNotNull(answer);
}
结果
自定义 advisor
advisor 的执行流程
节选自 spring AI 官方文档
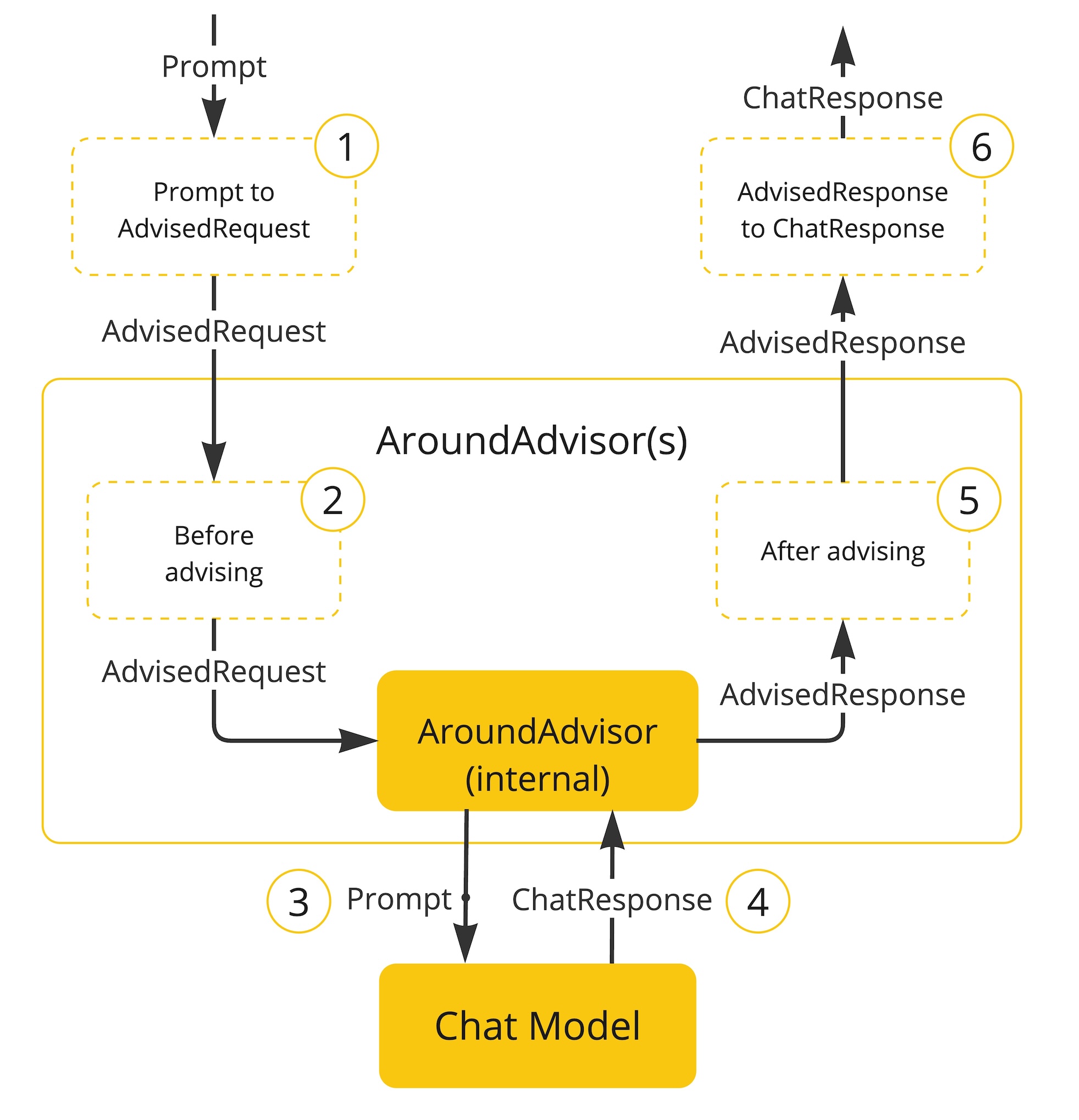
- Spring AI 框架将用户的 Prompt 封装为
AdvisedRequest对象,并创建空的AdvisorContext上下文。 - 链中每个 Advisor 依次处理请求并可进行修改,也可选择阻断请求(不调用下一实体)。若选择阻断,该 Advisor 需负责填充响应内容。
- 框架提供的最终 Advisor 将请求发送至聊天模型。
- 聊天模型的响应会逆向传回 Advisor 链,被转换为包含共享
AdvisorContext实例的AdvisedResponse对象。 - 每个 Advisor 均可处理或修改该响应。
- 通过提取
ChatCompletion内容,最终生成的AdvisedResponse将返回给客户端。
最佳实践 (官方文档)
- 保持 Advisor 功能单一化以提升模块性。
- 必要时通过
adviseContext在 Advisor 间共享状态。 - 同时实现流式与非流式版本以获得最佳灵活性。
- 谨慎规划 Advisor 链顺序以确保数据流正确。
观察型自定义advisor log
我们可以像在spring aop 一样 自己来定义切面 , 实现想要的结果 , 让日志输出我们想要的内容
在调用链中下一 Advisor 前后,分别记录 AdvisedRequest 和 AdvisedResponse。该实现仅观察请求与响应而不修改,同时支持非流式与流式场景。
自定义日志拦截器
这里我们直接复制 simpleloggerAdvisor 的代码 做一下精简就可以了
这里要注意使用 CallAroundAdvisor 和 StreamAroundAdvisor 如果不这么用 会出现无法捕捉到增强日志的情况
@Slf4j
public class JxLoveAppLoggerAdvisor implements CallAdvisor, StreamAdvisor {
public String getName() {
return this.getClass().getSimpleName();
}
public int getOrder() {
return 0;
}
private void logRequest(ChatClientRequest request) {
log.info("AI request {}", request.prompt().getUserMessage().getText());
}
private void logResponse(ChatClientResponse chatClientResponse) {
log.info("AI response {}", chatClientResponse.chatResponse().getResult().getOutput().getText());
}
public String toString() {
return SimpleLoggerAdvisor.class.getSimpleName();
}
public ChatClientResponse adviseCall(ChatClientRequest chatClientRequest, CallAdvisorChain callAdvisorChain) {
this.logRequest(chatClientRequest);
ChatClientResponse chatClientResponse = callAdvisorChain.nextCall(chatClientRequest);
this.logResponse(chatClientResponse);
return chatClientResponse;
}
public Flux<ChatClientResponse> adviseStream(ChatClientRequest chatClientRequest, StreamAdvisorChain streamAdvisorChain) {
this.logRequest(chatClientRequest);
Flux<ChatClientResponse> chatClientResponses = streamAdvisorChain.nextStream(chatClientRequest);
return (new ChatClientMessageAggregator()).aggregateChatClientResponse(chatClientResponses, this::logResponse);
}
}
增强型自定义advisor reReading
用来提高大模型接收问题的的能力 RE2这个拦截器用于让AI重复读提示词 来提升AI理解用户的问题
before方法通过应用重读技术增强用户输入查询。aroundCall方法拦截非流式请求并应用重读技术。aroundStream方法拦截流式请求并应用重读技术。- 通过设置
order值控制执行顺序 — 数值越小优先级越高。 - 为 Advisor 提供唯一标识名称。
public class ReReadingAdvisor implements BaseAdvisor {
private static final String DEFAULT_RE2_ADVISE_TEMPLATE = """
{re2_input_query}
Read the question again: {re2_input_query}
""";
private final String re2AdviseTemplate;
public ReReadingAdvisor() {
this(DEFAULT_RE2_ADVISE_TEMPLATE);
}
public ReReadingAdvisor(String re2AdviseTemplate) {
this.re2AdviseTemplate = re2AdviseTemplate;
}
@Override
public ChatClientRequest before(ChatClientRequest chatClientRequest, AdvisorChain advisorChain) {
String augmentedUserText = PromptTemplate.builder()
.template(this.re2AdviseTemplate)
.variables(Map.of("re2_input_query", chatClientRequest.prompt().getUserMessage().getText()))
.build()
.render();
return chatClientRequest.mutate()
.prompt(chatClientRequest.prompt().augmentUserMessage(augmentedUserText))
.build();
}
@Override
public ChatClientResponse after(ChatClientResponse chatClientResponse, AdvisorChain advisorChain) {
return chatClientResponse;
}
@Override
public int getOrder() {
return 0;
}
}
结构化输出
Spring AI 给我们提供了一种使用的机制 用于将大模型返回的文本 转换为结构化模式 比如 JSON XML
记得使用之前一定要确认 大模型支不支持结构化输出
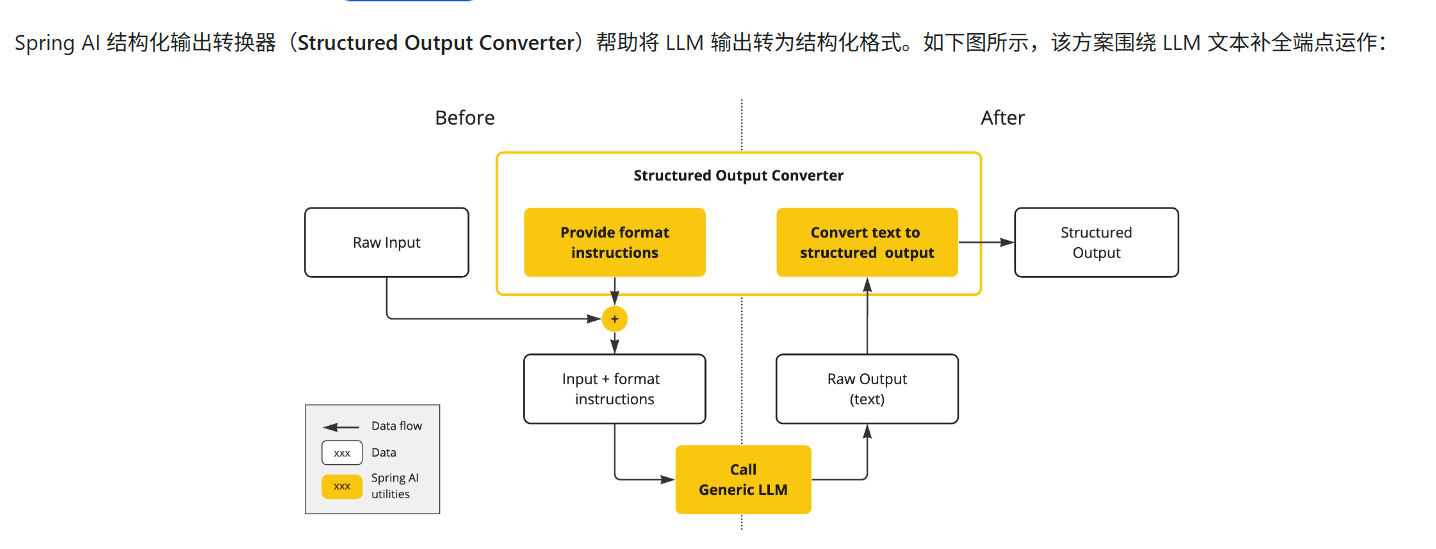
PS:
StructuredOutputConverter会尽力将模型输出转换为结构化格式,但 AI 模型并不保证按请求返回结构化输出(可能无法理解提示或生成所需结构)。建议实现验证机制以确保模型输出符合预期。
public interface StructuredOutputConverter<T> extends Converter<String, T>, FormatProvider {
}
FormatProvider 向 AI 模型提供特定格式指南,使其生成可被 Converter 转换为目标类型 T 的文本输出
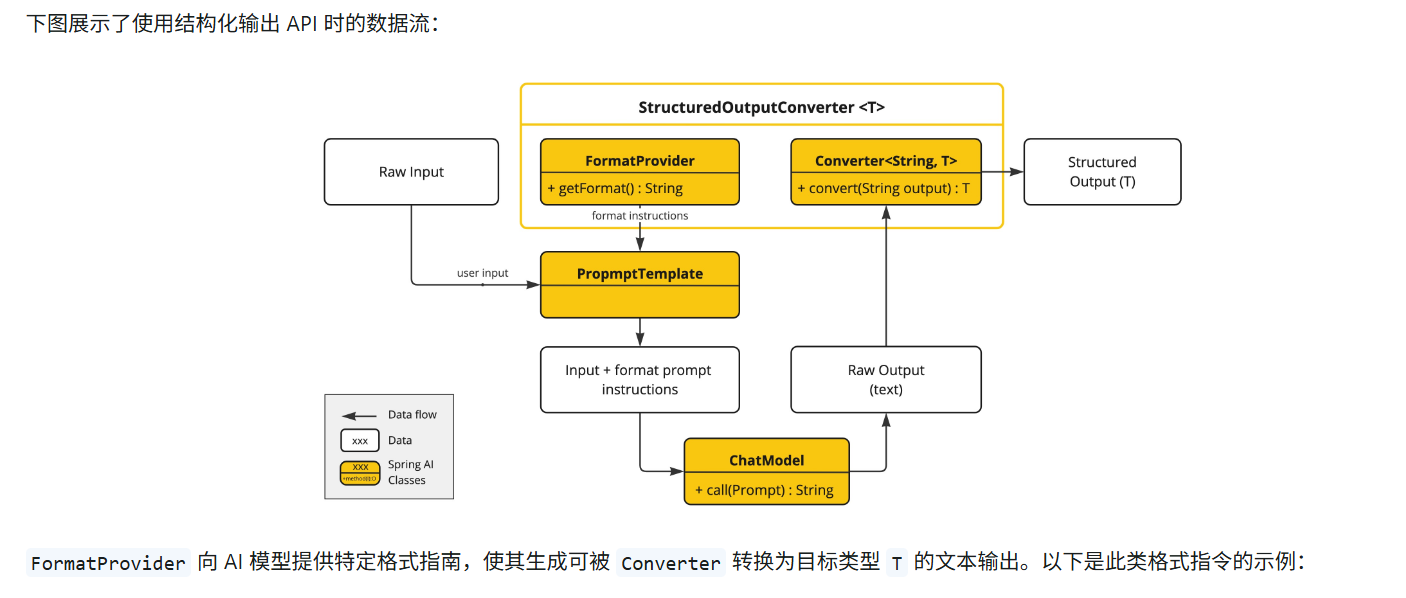
代码 在 LoveApp新增数据结构loveReport 和结构化输出方法
// 定义恋爱列表和标体
record loveReport(String title, List<String> suggestions) {
}
/**
* AI 结构化输出
*
* @author 冷环渊
* date: 2026/3/16 下午10:27
*/
public loveReport doChatWithReport(String message, String chatId) {
loveReport loveReport = chatClient
.prompt()
.system(SYSTEM_PROMPT + "每次对话都需要生成恋爱结果,标体为 {用户名} 的恋爱报告,内容为建议列表")
.user(message)
// chatid用于分离会话和设置记忆的上下文数量 控制篇幅和成本
.advisors(spec -> spec.param(ChatMemory.CONVERSATION_ID, chatId))
.call()
.entity(loveReport.class);
return loveReport;
}
}
这里我们可以看得到 我们调用大模型的方式从 获取响应 变成了 entity+自定义类型 这里就是spring AI 封装给我们的结构化输出方法 这里我们就可以获取到我们定义的数据结构的响应
对话记忆持久化
官方提供的持久化实在是太过的抽象 , 所以这里我们选择 自定义 chatmemory 来实现持久化
由于我们对于持久化的学习 不想要引入更多的第三方库和数据源 你也可以基于这个思路去自己实现拓展为 redis or mysql等数据库
这里我们采用使用 KRYO序列化库 直接序列化到文件中的方式来实现持久化 之后
依赖
<!-- 用来高性能序列化 Source: https://mvnrepository.com/artifact/com.esotericsoftware/kryo -->
<dependency>
<groupId>com.esotericsoftware</groupId>
<artifactId>kryo</artifactId>
<version>5.6.2</version>
</dependency>
创建 chatmemory 文件夹
FileBasedChatMemory
这里 spring ai 1.1 版本也是更新的get方法的参数 所以使用建造者模式创建
- 新增变量 MAX_MESSAGES 用于代替 原来get方法中的参数 lastN
/**
* @author 冷环渊
* @date 2026/3/18 下午7:44
* @description FileByteChatMemory
*/
public class FileBasedChatMemory implements ChatMemory {
private final String BASE_DIR;
private final int MAX_MESSAGES;
private static final Kryo kryo = new Kryo();
static {
// 关闭手动注册
kryo.setRegistrationRequired(false);
// 设置实例化策略
kryo.setInstantiatorStrategy(new StdInstantiatorStrategy());
}
//构造对象 指定文件目录
public FileBasedChatMemory(String baseDir, int maxMessages) {
this.BASE_DIR = baseDir;
this.MAX_MESSAGES = maxMessages;
File file = new File(BASE_DIR);
if (!file.exists()) {
file.mkdirs();
}
}
@Override
public void add(String conversationId, Message message) {
saveConversation(conversationId, message);
}
@Override
public void add(String conversationId, List<Message> messages) {
List<Message> conversationMessages = getOrCreateConversation(conversationId);
conversationMessages.addAll(messages);
saveConversation(conversationId, conversationMessages);
}
@Override
public List<Message> get(String conversationId) {
List<Message> allmessages = getOrCreateConversation(conversationId);
return allmessages.stream()
.skip(Math.max(0, allmessages.size() - MAX_MESSAGES))
.toList();
}
@Override
public void clear(String conversationId) {
File conversationFile = getConversationFile(conversationId);
if (conversationFile.exists()) {
conversationFile.delete();
}
}
/**
* 获取 或创建会话消息列表
*
* @author 冷环渊
* date: 2026/3/18 下午7:54
*/
private List<Message> getOrCreateConversation(String conversationId) {
File file = getConversationFile(conversationId);
List<Message> messages = new ArrayList<>();
if (file.exists()) {
try (Input input = new Input(new FileInputStream(file))) {
messages = kryo.readObject(input, ArrayList.class);
} catch (FileNotFoundException e) {
throw new RuntimeException(e);
}
}
return messages;
}
private void saveConversation(String conversationId, List<Message> messages) {
File file = getConversationFile(conversationId);
try (Output output = new Output(new FileOutputStream(file))) {
kryo.writeObject(output, messages);
} catch (FileNotFoundException e) {
throw new RuntimeException(e);
}
}
private void saveConversation(String conversationId, Message messages) {
File file = getConversationFile(conversationId);
try (Output output = new Output(new FileOutputStream(file))) {
kryo.writeObject(output, messages);
} catch (FileNotFoundException e) {
throw new RuntimeException(e);
}
}
/**
* 创造的每个会话文件单独保存
*
* @author 冷环渊
* date: 2026/3/18 下午7:54
*/
private File getConversationFile(String conversationId) {
return new File(BASE_DIR, conversationId + ".kryo");
}
public static FileBasedChatMemory.Builder builder() {
return new FileBasedChatMemory.Builder();
}
public static final class Builder {
private String baseDir;
private int maxMessages = 10;
private Builder() {
}
public FileBasedChatMemory.Builder maxMessages(int maxMessages) {
this.maxMessages = maxMessages;
return this;
}
public FileBasedChatMemory.Builder baseDir(String baseDir) {
this.baseDir = baseDir;
return this;
}
public FileBasedChatMemory build() {
return new FileBasedChatMemory(this.baseDir, this.maxMessages);
}
}
}
在 loveAPP构造方法修改 chetmemory 改为我们自己定义的
public LoveApp(ChatModel dashScopeChatModel) {
// ChatMemory chatMemory = new InMemoryChatMemory();
String fileDir = System.getProperty("user.dir") + "/tmp/chat-memory";
FileBasedChatMemory chatMemory = new FileBasedChatMemory(fileDir);
chatClient = ChatClient.builder(dashScopeChatModel)
.defaultSystem(SYSTEM_PROMPT)
.defaultAdvisors(
//自定义拦截器
new JxLoveAppLoggerAdvisor(),
// 在需要的时候开启 new ReReadingAdvisor(),
MessageChatMemoryAdvisor.builder(chatMemory).build()
)
.build();
}
效果
promptTemplate
基础理念
spring 提供给我们的类似 JSP 一样的 动态变量模版
Spring AI 框架中用于构建和管理提示词的核心组件。允许开发者创建带有占位符的文本模板,然后在运行时动态替换这些占位符。
案例
Strig template = "你好,{name}。今天是{day},天气weather}。";
PromptTemlate promptTemplate = new PromptTemplae(template);
Map<String, Object> variables = new HashMap<>();
variables.put("name", "小冷");
variables.put("day", "星期一");
variables.put("weather", "晴朗");
String prompt = promptTemplate.render(variables);
底层基于 一个叫 OSS String tamplate的强大字符串引擎
Spring AI 通过 TemplateRenderer 接口处理模板字符串中的变量替换,默认实现使用 [StringTemplate]。若需自定义逻辑,可提供自己的 TemplateRenderer 实现。对于无需模板渲染的场景(如模板字符串已完整),可使用提供的 NoOpTemplateRenderer。
案例
PromptTemplate promptTemplate = PromptTemplate.builder()
.renderer(StTemplateRenderer.builder().startDelimiterToken('<').endDelimiterToken('>').build())
.template("""
Tell me the names of 5 movies whose soundtrack was composed by <composer>.
""")
.build();
String prompt = promptTemplate.render(Map.of("composer", "John Williams"));
从文件加载模板
PromptTemplate 支持从外部文件加载模板内容,很适合管理复杂的提示词。Spring AI 利用 Spring 的 Resource 对象来从指定路径加载模板文件:
@Value("classpath:/prompts/system-message.st")
private Resouce systemResource;
SystemPromptemplate systemPromptTemplate = new SystemPromptTemplae(systemResource);
这种方式让你可以:
- 将复杂的提示词放在单独的文件中管理
- 在不修改代码的情况下调整提示词
- 为不同场景准备多套提示词模板
推荐大家使用 这种方式来管理自己的 提示词模板
多模态
AI 多模态 可以同时处理图片 视频 音频 文字等多种信息途径的大模型 , 现在比如 qwen3.5 是原生多模态大模型 将多种不同信息源一起训练 这样的设计可以让大模型可以捕获更多跨模态特征之间的复杂关系
检索增强生成 RAG
基础知识
检索增强生成(Retrieval Augmented Generation, RAG)是一种有用的技术,用于克服大型语言模型在长篇内容、事实准确性和上下文感知方面的局限性。
通过RAG 增强过后 以从外部知识库检索提供给大模型的方式,提升AI回答专业特定内容问题和给出更准确的建议的能力
如果不给 AI 提供特定领域的知识库,AI 可能会面临这些问题:
- 知识有限:AI 不知道你的最新课程和内容
- 编故事:当 AI 不知道答案时,它可能会 “自圆其说” 编造内容
- 无法个性化:不了解你的特色服务和回答风格
- 不会推销:不知道该在什么时候推荐你的付费课程和服务S
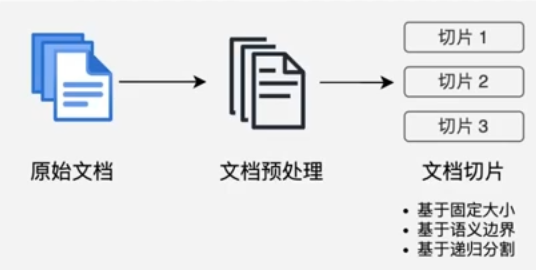
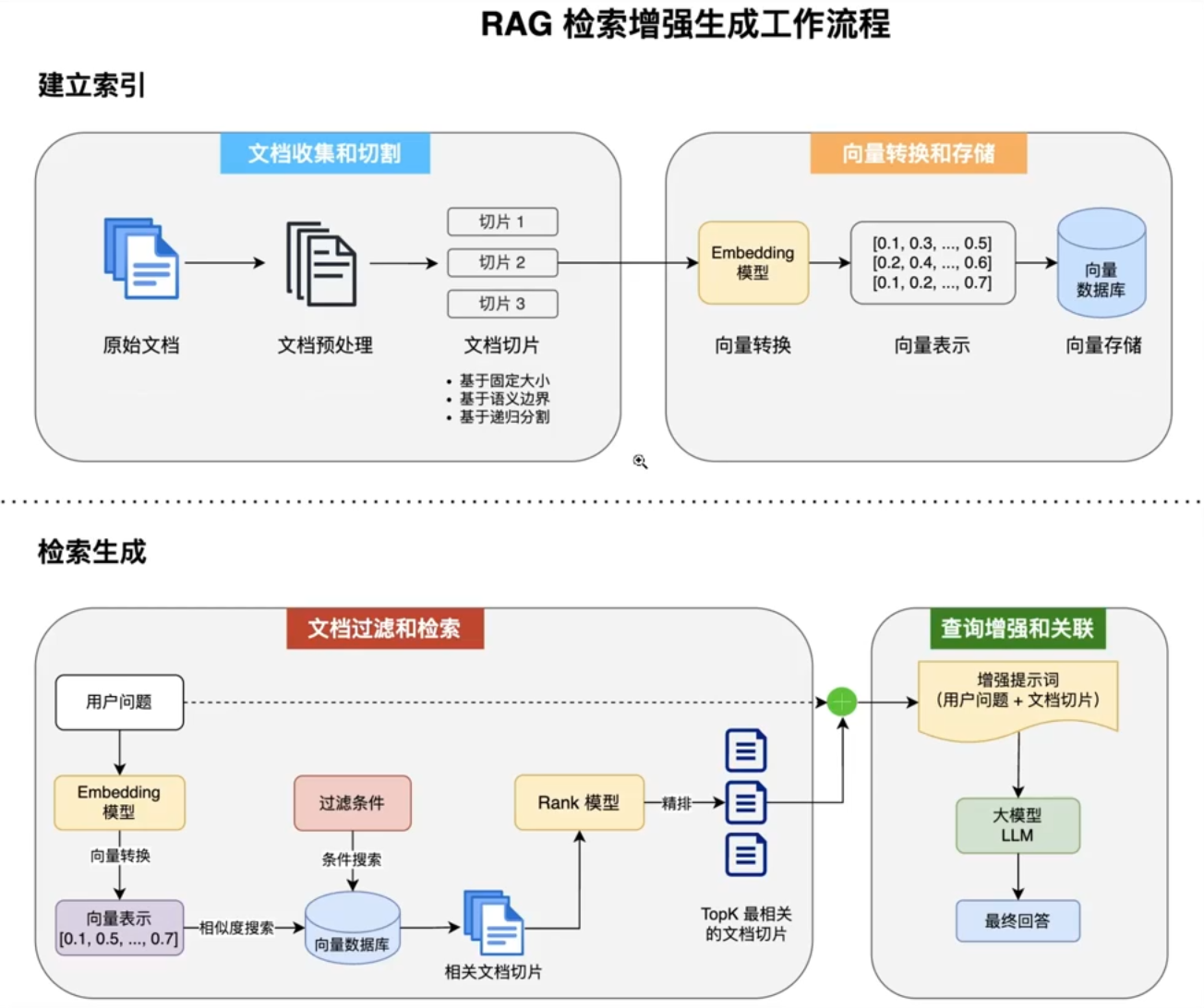
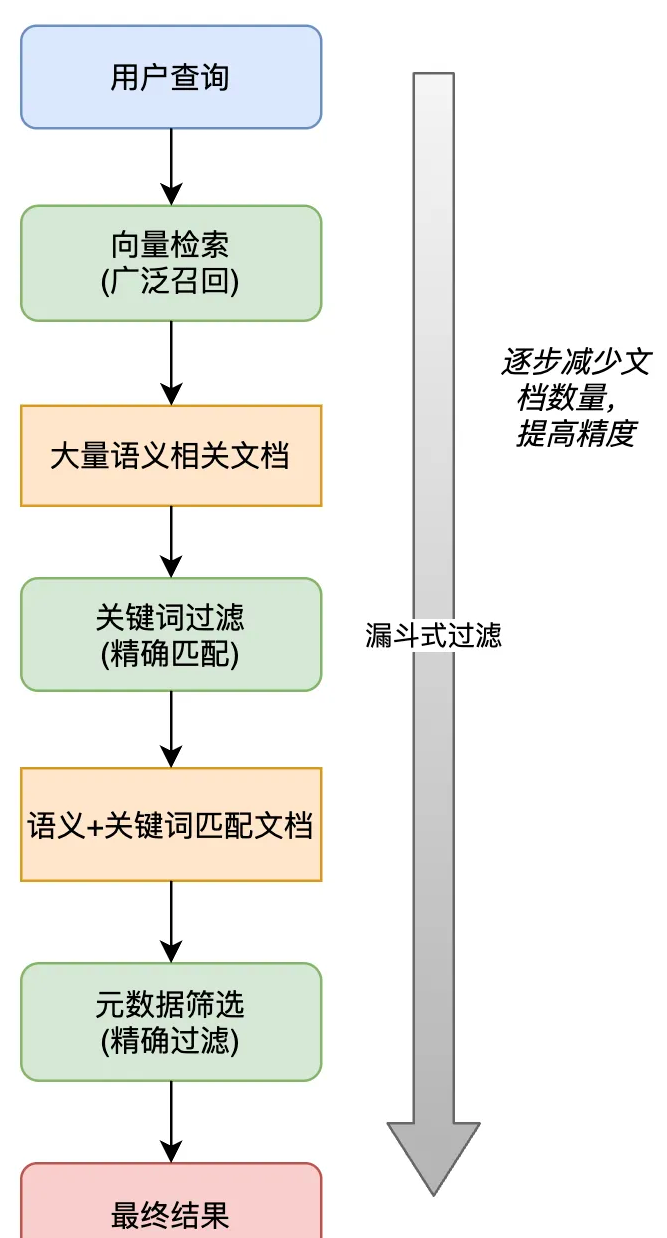
我们将 RAG技术主要分为四个核心步骤:
-
文档收集和切割
-
文档收集:从各种来源(网页、PDF、数据库等)收集原始文档
-
文档预处理:清洗、标准化文本格式
-
文档切割:将长文档分割成适当大小的片段
- 基于固定大小(如 512 个 token)
- 基于语义边界(如段落、章节)
- 基于递归分割策略(如递归字符 n-gram 切割)
-
向量转换和存储
- 向量转换:使用 Embedding 模型将文本块转换为高维向量表示,可以捕获到文本的语义特征
- 向量存储:将生成的向量和对应文本存入向量数据库,支持高效的相似性搜索

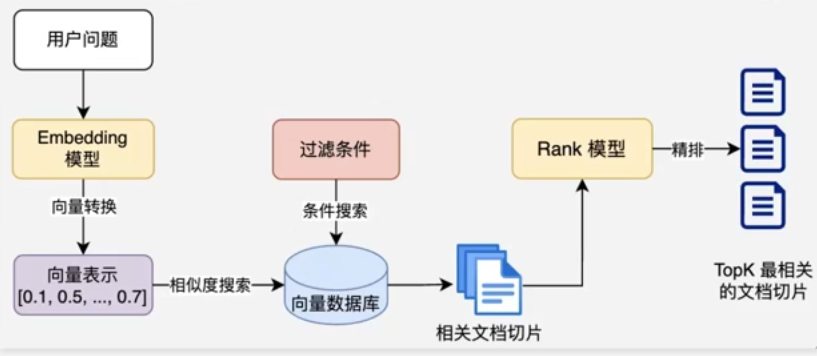
-
文档过滤和检索
-
查询处理:将用户问题也转换为向量表示
-
过滤机制:基于元数据、关键词或自定义规则进行过滤
-
相似度搜索:在向量数据库中查找与问题向量最相似的文档块,常用的相似度搜索算法有余弦相似度、欧氏距离等
-
排序后 根据模型再筛选出更贴合问题的 topk 最后选出最高的N项 加入到大模型的提示词
-
上下文组装:将检索到的多个文档块组装成连贯上下文
-
-
查询增强和关联
- 提示词组装:将检索到的相关文档与用户问题组合成增强提示
- 上下文融合:大模型基于增强提示生成回答
- 源引用:在回答中添加信息来源引用
- 后处理:格式化、摘要或其他处理以优化最终输出
完整的工作流程
Embedding模型
Embedding 嵌入是将高维离散数据(如文字、图片)转换为低维连续向量的过程。这些向量能在数学空间中表示原始数据的语义特征,使计算机能够理解数据间的相似性。
Embedding 模型是执行这种转换算法的机器学习模型,如 Word2Vec(文本)、ResNet(图像)等。不同的 Embedding 模型产生的向量表示和维度数不同,一般维度越高表达能力更强,可以捕获更丰富的语义信息和更细微的差别,但同样占用更多存储空间
向量数据库
向量数据库是专门存储和检索向量数据的数据库系统。通过高效索引算法实现快速相似性搜索,支持 K 近邻查询等操作。

召回
召回是信息检索中的第一阶段,目标是从大规模数据集中快速筛选出可能相关的候选项子集。强调速度和广度,而非精确度。
精排和 Rank 模型
精排(精确排序)是搜索 / 推荐系统的最后阶段,使用计算复杂度更高的算法,考虑更多特征和业务规则,对少量候选项进行更复杂、精细的排序。
比如,短视频推荐先通过召回获取数万个可能相关视频,再通过粗排缩减至数百条,最后精排阶段会考虑用户最近的互动、视频热度、内容多样性等复杂因素,确定最终展示的 10 个视频及顺序。
Rank 模型(排序模型)负责对召回阶段筛选出的候选集进行精确排序,考虑多种特征评估相关性。

混合检索策略(常用)
混合检索策略结合多种检索方法的优势,提高搜索效果。常见组合包括关键词检索、语义检索、知识图谱等。
在使用费混合检索策略的时候 推荐将语义的权重 设置为 0.7 左右 更加的通用
Spring AI RAG+本地知识库+云知识库
Spring AI 使用 Advisor API 为常见的 RAG 流提供开箱即用的支持
制作一些简单的md文件 存到 类路径下
ETL
提取、转换和加载 (ETL) 框架是检索增强生成 (RAG) 用例中数据处理的支柱。
ETL 管道协调从原始数据源到结构化向量存储的数据流,确保数据以最优格式供 AI 模型检索。
RAG 用例通过从数据主体中检索相关信息来增强生成模型的能力,从而提高生成输出的质量和相关性。
工作流程

Document 类包含文本、元数据以及可选的附加媒体类型,如图像、音频和视频。
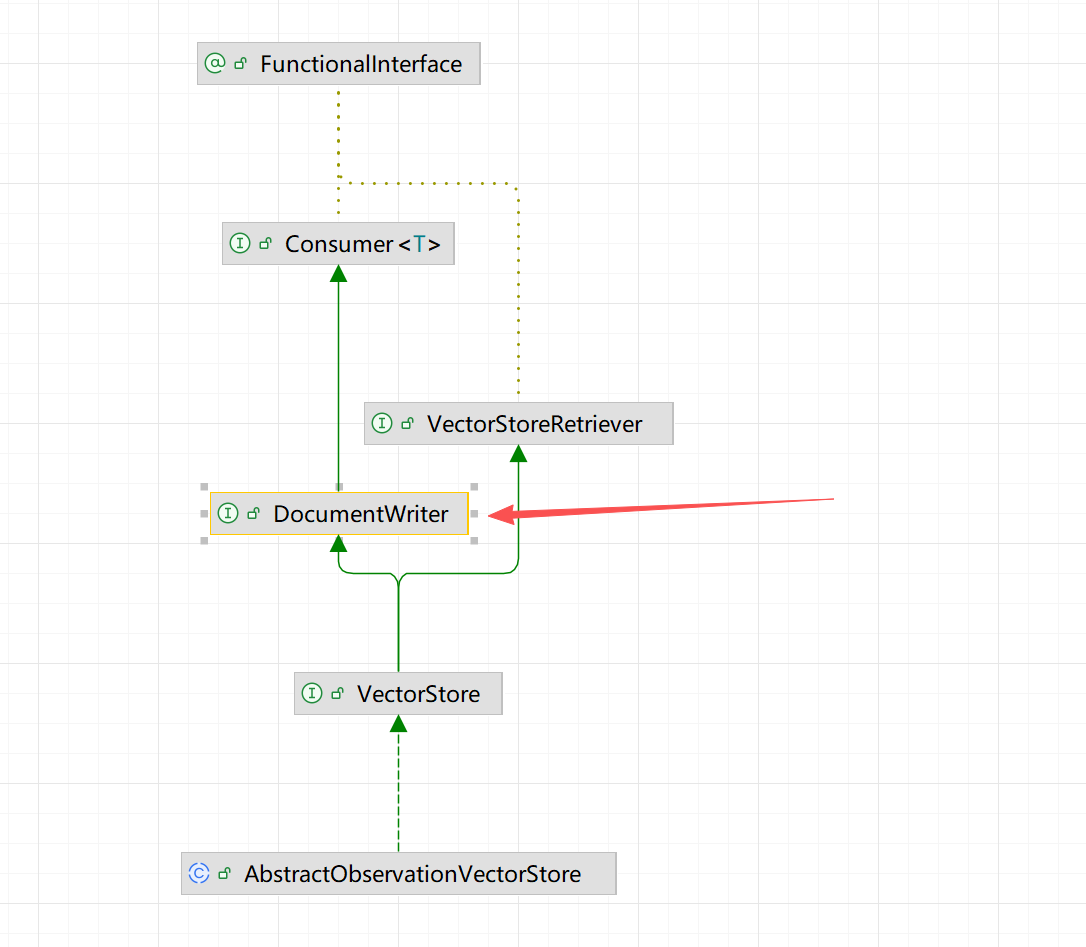
ETL 管道有三个主要组件:
DocumentReader实现了Supplier<List<Document>>DocumentTransformer实现了Function<List<Document>, List<Document>>DocumentWriter实现了Consumer<List<Document>>
Document 类的内容是通过 DocumentReader 从 PDF、文本文件和其他文档类型创建的。
读取document
我们准备用 md格式的文件来构建一个简单的知识库 所以需要引入spring ai 读取md文件的依赖
<!-- Source: https://mvnrepository.com/artifact/org.springframework.ai/spring-ai-markdown-document-reader -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-markdown-document-reader</artifactId>
<version>1.1.3</version>
<scope>compile</scope>
</dependency>
知识库读取类
package com.hyc.jxaiagent.rag;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.markdown.MarkdownDocumentReader;
import org.springframework.ai.reader.markdown.config.MarkdownDocumentReaderConfig;
import org.springframework.core.io.Resource;
import org.springframework.core.io.support.ResourcePatternResolver;
import org.springframework.stereotype.Component;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
/**
* @author 冷环渊
* @date 2026/3/23 下午3:50
* @description LoveAppDocumentLoader
* 用于 加载 md RAG知识库
*/
@Component
@Slf4j
public class LoveAppDocumentLoader {
private final ResourcePatternResolver resourcePatternResolver;
public LoveAppDocumentLoader(ResourcePatternResolver resourcePatternResolver) {
this.resourcePatternResolver = resourcePatternResolver;
}
public List<Document> loadMarkdowns() {
List<Document> allDocument = new ArrayList<>();
//加载多个markdown 文件
log.info("开始加载RAG知识库");
try {
Resource[] resources = resourcePatternResolver.getResources("classpath:document/*.md");
for (Resource resource : resources) {
String filename = resource.getFilename();
MarkdownDocumentReaderConfig config = MarkdownDocumentReaderConfig.builder()
.withHorizontalRuleCreateDocument(true)
.withIncludeCodeBlock(false)
.withIncludeBlockquote(false)
.withAdditionalMetadata("filename", filename)
.build();
MarkdownDocumentReader reader = new MarkdownDocumentReader(resource, config);
allDocument.addAll(reader.get());
}
} catch (IOException e) {
log.error("加载 Markdown 文件失败 ", e);
}
return allDocument;
}
}
会帮我们按照文件名分段的加载 md文件中的数据
使用向量数据库
这里我们使用 spring 给我们内部集成的一个基于内存的向量数据库 SimpleVectorStore
SimpleVectorStore 实现了 VectorStore 接口,而 VectorStore 接口集成了 DocumentWriter,所以具备文档写入能力
/**
* @author 冷环渊
* @date 2026/3/23 下午5:39
* @description LoveAppVectorStoreConfig
* 恋爱大师向量数据库配置 初始化基于内存的向量数据库 bean
*/
@Component
@Slf4j
public class LoveAppVectorStoreConfig {
@Resource
private LoveAppDocumentLoader loveAppDocumentLoader;
@Bean
public VectorStore LoveAppVectorStore(EmbeddingModel dashScopeModel) {
log.info("初始化基于内存的向量数据库");
SimpleVectorStore simpleVectorStore = SimpleVectorStore.builder(dashScopeModel).build();
List<Document> documents = loveAppDocumentLoader.loadMarkdowns();
simpleVectorStore.doAdd(documents);
return simpleVectorStore;
}
}
问答增强
spring 提供了两种 增强 Advisor RetrievalAugmentationAdvisor 这里我们先试用更为简单的QuestionAnswerAdvisor
引入依赖
<!--用于RAG 写入提示词增强 Source: https://mvnrepository.com/artifact/org.springframework.ai/spring-ai-advisors-vector-store -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
<version>1.1.3</version>
<scope>compile</scope>
</dependency>
QuestionAnswerAdvisor
在 loveApp中 加入新方法
@Resource
private VectorStore loveAppVectorStore;
/**
* 基于 本地知识库+向量模型使用
*
* @author 冷环渊
* date: 2026/3/23 下午5:47
*/
public String doChatWithRag(String message, String chatId) {
ChatResponse chatResponse = chatClient
.prompt()
.user(message)
.advisors(spec -> spec.param(ChatMemory.CONVERSATION_ID, chatId))
.advisors(new QuestionAnswerAdvisor(loveAppVectorStore))
.call()
.chatResponse();
String content = chatResponse.getResult().getOutput().getText();
log.info("content: {}", content);
return content;
}
测试案例
@Test
void doChatRag() {
String chatId = UUID.randomUUID().toString();
String message = "我已经结婚了 但是我婚后的亲密关系一直在下降 婚后与伴侣家人产生矛盾,如何妥善解决 ";
String answer = loveApp.doChatWithRag(message, chatId);
Assertions.assertNotNull(answer);
}
效果 可以看出 我们的文本增强已经依据数据库实现了

云知识库
在百炼云平台 创建一个 云知识库
使用云知识库 快速的集成spring ai alibaba 快速的实现 切片rank等云服务厂商提供的便利服务
缺点就是 有开销 信息不保密等
这里我们使用 RetrievalAugmentationAdvisor 来连接云知识库 这里基于百炼sdk 来实现
新建配置类 并且更改love APP 入口中的方法
配置 advisor
/**
* @author 冷环渊
* @date 2026/3/23 下午5:39
* @description LoveAppVectorStoreConfig
* 恋爱大师向量数据库配置 基于阿里云知识库方法
*/
@Component
@Slf4j
public class LoveAppCloudRAGAdvisorConfig {
@Value("${spring.ai.dashscope.api-key}")
private String dashScopeApiKey;
@Bean
public Advisor LoveAppCloudRAGAdvisor() {
log.info("初始化基于云的RAG");
DashScopeApi dashScopeApi = DashScopeApi.builder()
.apiKey(dashScopeApiKey)
.build();
final String KONWLADGE_INDEX = "恋爱大师智能体";
DashScopeDocumentRetriever dashScopeDocumentRetriever = new DashScopeDocumentRetriever(dashScopeApi,
DashScopeDocumentRetrieverOptions.builder().withIndexName(KONWLADGE_INDEX)
.build());
return RetrievalAugmentationAdvisor.builder()
.documentRetriever(dashScopeDocumentRetriever)
.build();
}
}
修改love app
/**
* 基于 本地知识库+向量模型使用
*
* @author 冷环渊
* date: 2026/3/23 下午5:47
*/
public String doChatWithRag(String message, String chatId) {
ChatResponse chatResponse = chatClient
.prompt()
.advisors(spec -> spec.param(ChatMemory.CONVERSATION_ID, chatId))
//启用advisor 本地知识库问答增强服务
// .advisors(QuestionAnswerAdvisor.builder(loveAppVectorStore).build())
//基于云知识库 检索增强
.advisors(LoveAppCloudRAGAdvisor)
.advisors(new JxLoveAppLoggerAdvisor())
.user(message)
.call()
.chatResponse();
String content = chatResponse.getResult().getOutput().getText();
log.info("content: {}", content);
return content;
}
效果

可以看出 在切片和命中还有提示词方面 云知识库和本地知识库还是有区别的
RAG 进阶
extract 提取
Spring AI 通过 DocumentReader 组件实现文档抽取,也就是把文档加载到内存中。
看下源码,DocumentReader 接口实现了 Supplier<List<Document>> 接口,主要负责从各种数据源读取数据并转换为 Document 对象集合。
spring ai 和 alibaba 提供了很多可以参考的提取类案例 有需要可以直接去官网查看和学习
public interface DocumentReader extends Supplier<List<Document>> {
default List<Document> read() {
return get();
}
}
Transformer 转换
Spring AI 通过 DocumentTransformer 组件实现文档转换。
看下源码,DocumentTransformer 接口实现了 Function<List<Document>, List<Document>> 接口,负责将一组文档转换为另一组文档。
public interface DocumentTransformer extends Function<List<Document>, List<Document>> {
default List<Document> transform(List<Document> documents) {
return apply(documents);
}
}
文档转换是保证 RAG 效果的核心步骤,也就是如何将大文档合理拆分为便于检索的知识碎片,Spring AI 提供了多种 DocumentTransformer 实现类,可以简单分为 3 类。
- 文本分割
- 元数据增强(常用)
- 内容格式化工具
Load加载
Spring AI 通过 DocumentWriter 组件实现文档加载(写入)。
DocumentWriter 接口实现了 Consumer<List<Document>> 接口,负责将处理后的文档写入到目标存储中:
public interface DocumentWriter extends Consumer<List<Document>> {
default void write(List<Document> documents) {
accept(documents);
}
}
Spring AI 提供了 2 种内置的 DocumentWriter 实现:
1)FileDocumentWriter:将文档写入到文件系统
@Component
class MyDocumentWriter {
public void writeDocuments(List<Document> documents) {
FileDocumentWriter writer = new FileDocumentWriter("output.txt", true, MetadataMode.ALL, false);
writer.accept(documents);
}
}
2)VectorStoreWriter:将文档写入到向量数据库
@Component
class MyVectorStoreWriter {
private final VectorStore vectorStore;
MyVectorStoreWriter(VectorStore vectorStore) {
this.vectorStore = vectorStore;
}
public void storeDocuments(List<Document> documents) {
vectorStore.accept(documents);
}
}
当然,你也可以同时将文档写入多个存储,只需要创建多个 Writer 或者自定义 Writer 即可。
RAG最佳实践调优
文档收集和切割
文档的质量决定了 AI 回答能力的上限,其他优化策略只是让 AI 回答能力不断接近上限。所以处理好文档是RAG系统中最基础和重要的环节
优化原始文档
知识完备性 是文档质量的首要条件。如果知识库缺失相关内容,大模型将无法准确回答对应问题。我们需要通过收集用户反馈或统计知识库检索命中率,不断完善和优化知识库内容。
在知识完整的前提下,我们要注意 3 个方面:
1)内容结构化:
- 原始文档应保持排版清晰、结构合理,如案例编号、项目概述、设计要点等
- 文档的各级标题层次分明,各标题下的内容表达清晰
- 列表中间的某一条之下尽量不要再分级,减少层级嵌套
2)内容规范化:
- 语言统一:确保文档语言与用户提示词一致(比如英语场景采用英文文档),专业术语可进行多语言标注
- 表述统一:同一概念应使用统一表达方式(比如 ML、Machine Learning 规范为 “机器学习”),可通过大模型分段处理长文档辅助完成
- 减少噪音:尽量避免水印、表格和图片等可能影响解析的元素
3)格式标准化:
- 优先使用 Markdown、DOC/DOCX 等文本格式(PDF 解析效果可能不佳),可以通过百炼 DashScopeParse 工具将 PDF 转为 Markdown,再借助大模型整理格式
- 如果文档包含图片,需链接化处理,确保回答中能正常展示文档中的插图,可以通过在文档中插入可公网访问的 URL 链接实现
我们可以尝试专门用AI来为 AI 知识库创作的文档。我们可以将上述规则输入给 AI 大模型,让它对已有文档进行优化。
文档切片
根据不同的领域和知识库的需要进行适量合理的文档切片, 对检索效果有着至关重要的影响
文档的切片应当避免:
- 对于专业文献 尽可能的保留更多的上下文信息, 对于社交 娱乐类的文档 则尽量的缩短长度 使用更准确的语义
- 如果用户的提示词 复杂且具体 也需要增加切片长度 反之可以适量的缩短
如果不做切片 就会出现上下文冗长 ,不同切片段落问题导致语义缺失,和明显的语义截断
最好的切片策略
AI+人工二次校验 ,首先使用分块算法,基于句号或其他标识符 分为段落 然后根据语义切割
切片官方示例(不太推荐)
spring ai ETL给我们提供了 DocumentTransformer 可以自己来调整切分规则
@Component
class MyTokenTextSplitter {
public List<Document> splitDocuments(List<Document> documents) {
TokenTextSplitter splitter = new TokenTextSplitter();
return splitter.apply(documents);
}
public List<Document> splitCustomized(List<Document> documents) {
TokenTextSplitter splitter = new TokenTextSplitter(200, 100, 10, 5000, true);
return splitter.apply(documents);
}
}
我们人工代码切词 会出现切出奇怪的文案的问题 这里我们更推荐 使用云服务厂商提供给我们的已经切的七七八八的知识库, 切分出来 更加的合理一些
采用智能切分策略时,云知识库会:
- 首先利用系统内置的分句标识符将文档划分为若干段落
- 基于划分的段落,根据语义相关性自适应地选择切片点进行切分,而非根据固定长度切分
这种方法能更好地保障文档语义完整性,避免不必要的断裂。这一策略将应用于知识库中的所有文档(包括后续导入的文档)。
此外,建议在文档导入知识库后进行一次人工检查,确认文本切片内容的语义完整性和正确性。如果发现切分不当或解析错误,可以直接编辑文本切片进行修正:
我们可以人工二次的去再次审核一下切片的内容 从而获得理想的文本切片
元信息 metadata
这里可以理解成 每段文本的标签 , 我们可以根据这些标签去更精确的定位到需要的切片
手动添加
可以使用 documentReader 来批量的添加元信息
修改 LoveAppDocumentLoader
public List<Document> loadMarkdowns() {
List<Document> allDocument = new ArrayList<>();
//加载多个markdown 文件
log.info("开始加载RAG知识库");
try {
Resource[] resources = resourcePatternResolver.getResources("classpath:document/*.md");
for (Resource resource : resources) {
String filename = resource.getFilename();
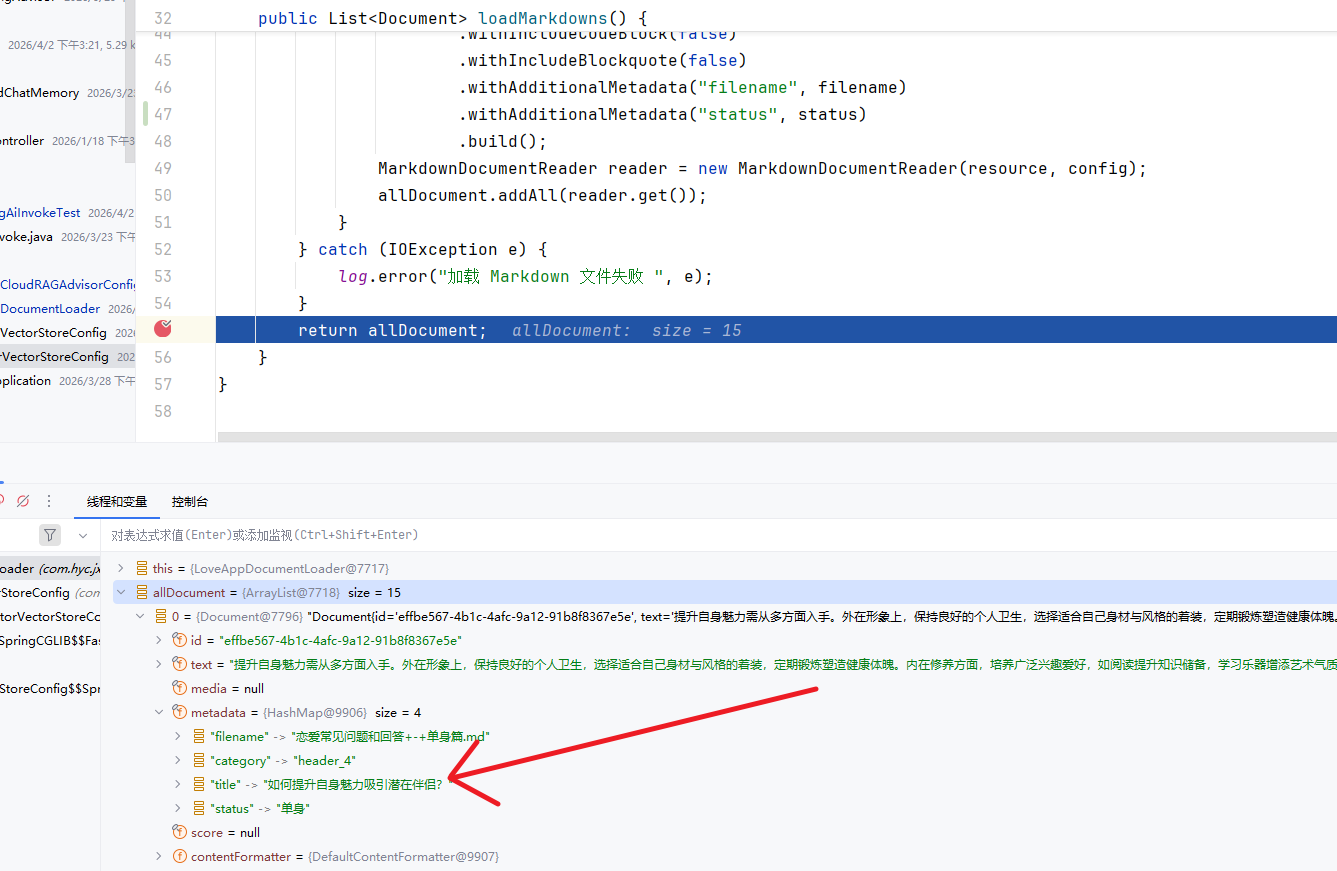
//在读取文档的过程中 提取文档名分类加入到标签
String status = filename.substring(filename.length() - 4, filename.length() - 6);
MarkdownDocumentReaderConfig config = MarkdownDocumentReaderConfig.builder()
.withHorizontalRuleCreateDocument(true)
.withIncludeCodeBlock(false)
.withIncludeBlockquote(false)
.withAdditionalMetadata("filename", filename)
.withAdditionalMetadata("status", status)
.build();
MarkdownDocumentReader reader = new MarkdownDocumentReader(resource, config);
allDocument.addAll(reader.get());
}
} catch (IOException e) {
log.error("加载 Markdown 文件失败 ", e);
}
return allDocument;
}
效果
自动添加
Spring AI 提供了生成元信息的 Transformer 组件,可以基于 AI 自动解析关键词并添加到元信息中。代码如下:
自动补充关键词
/**
* @author 冷环渊
* @date 2026/4/2 下午3:33
* @description MyKeywordEnricher
* 可以基于 AI 自动解析关键词并添加到元信息
*/
@Component
public class MyKeywordEnricher {
@Resource
private ChatModel dashscopeChatModel;
List<Document> enrichDocuments(List<Document> documents) {
KeywordMetadataEnricher enricher = new KeywordMetadataEnricher(this.dashscopeChatModel, 5);
return enricher.apply(documents);
}
}
LoveAppVectorStoreConfig中使用KeywordEnricher
@Bean
@Primary
public VectorStore LoveAppVectorStore(EmbeddingModel dashScopeModel) {
log.info("初始化基于内存的向量数据库");
SimpleVectorStore simpleVectorStore = SimpleVectorStore.builder(dashScopeModel).build();
List<Document> documents = loveAppDocumentLoader.loadMarkdowns();
//自动补充关键词元信息
List<Document> enrichDocuments = myKeywordEnricher.enrichDocuments(documents);
simpleVectorStore.doAdd(enrichDocuments);
return simpleVectorStore;
}
效果
可以看到 AI 增强后 帮我们提取了五个关键词
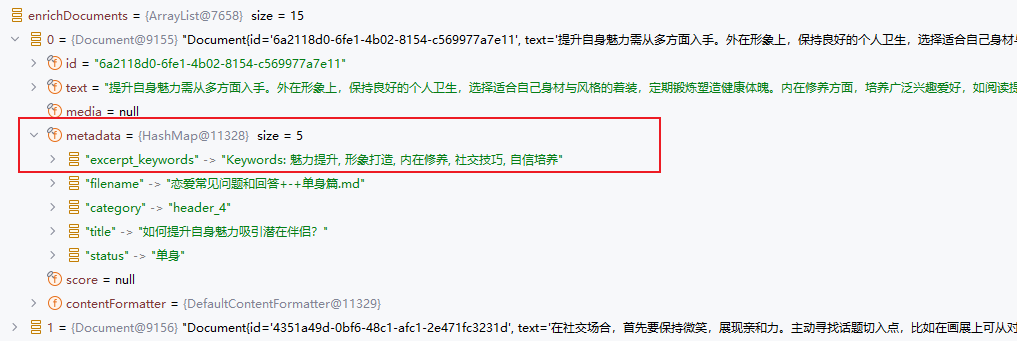
云RAG设置
阿里百炼提供的知识库 中元信息一旦生成就无法修改了 这很不OK
这里我们还是推荐自己对文档设置好标签 如果一定要使用 RAG 那么要在创建知识库前 设置好需要的元信息
向量存储和转换
这里就是技术选型 :
- 云服务向量数据库
- 自己部署的向量数据库
- 学习用的内存中的向量数据库
还有选择合适的嵌入模型 比如 阿里的 text-embedding-v4
文本过滤和检索(最能体现技术)
这里是程序员展示技术的阶段了 , 优化好这个环节可以显著的提升系统整体的使用效果
多查询扩展(慎用这种优化方式)
多轮对话中 用户输入的提示词可能不够完整 会产生歧义
使用多查询扩展时,要注意:
- 设置合适的查询数量(建议 3 - 5 个),过多会影响性能、增大成本
- 保留原始查询的核心语义
在编程实现中,可以通过以下代码实现多查询扩展:
测试
@Component
public class multiQueryExpanderDemo {
private final ChatClient.Builder chatClientBuilder;
public multiQueryExpanderDemo(ChatClient.Builder chatClientBuilder) {
this.chatClientBuilder = chatClientBuilder;
}
public List<Query> expand(String query) {
MultiQueryExpander queryExpander = MultiQueryExpander.builder()
.chatClientBuilder(chatClientBuilder)
.numberOfQueries(3)
.build();
List<Query> queries = queryExpander.expand(new Query(query));
return queries;
}
}
测试
@SpringBootTest
class multiQueryExpanderDemoTest {
@Resource
private multiQueryExpanderDemo multiQueryExpanderDemo;
@Test
void expand() {
List<Query> expand = multiQueryExpanderDemo.expand("谁是冷环渊啊 到底是不是人类啊?");
Assertions.assertNotNull(expand);
}
}
效果
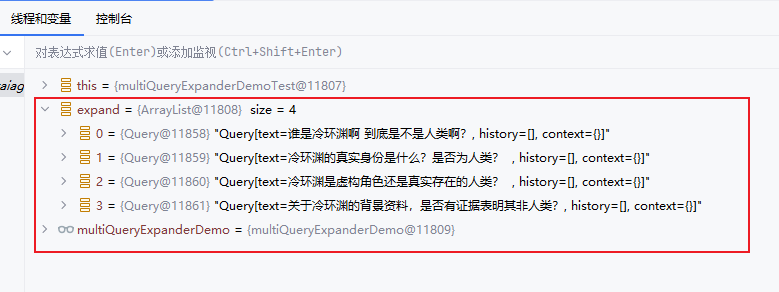
💡 需要注意,多查询扩展会增加查询次数和计算成本,效果也不易量化评估,所以个人建议慎用这种优化方式。
PS: 如果有多模型的话 可以用token比较便宜的模型来做查询拓展 然后把组合好的Prompt 给主模型回复
获得扩展查询后,可以直接用于检索文档、或者提取查询文本来改写提示词:
多查询扩展的完整使用流程可以包括三个步骤:
- 使用扩展后的查询召回文档:遍历扩展后的查询列表,对每个查询使用
DocumentRetriever来召回相关文档。 - 整合召回的文档:将每个查询召回的文档进行整合,形成一个包含所有相关信息的文档集合。(也可以使用 文档合并器 去重)
- 使用召回的文档改写 Prompt:将整合后的文档内容添加到原始 Prompt 中,为大语言模型提供更丰富的上下文信息。
查询重写和解释(推荐的优化方式)
查询重写和翻译可以使查询更加精确和专业,但是要注意保持查询的语义完整性。
适用于提示词想要检索的更加精确, 如果是想要得到更多方向的回答则不推荐这么优化
主要应用包括:
- 使用
RewriteQueryTransformer优化查询结构 - 配置
TranslationQueryTransformer支持多语言
查询重写器
package com.hyc.jxaiagent.rag;
/**
* @author 冷环渊
* @date 2026/4/2 下午4:05
* @description QueryRewriter
* 使用查询重写器 优化查询结构
*/
@Component
public class QueryRewriter {
private final QueryTransformer queryTransformer;
public QueryRewriter(ChatModel dashscopeChatModel) {
ChatClient.Builder builder = ChatClient.builder(dashscopeChatModel);
queryTransformer = RewriteQueryTransformer.builder()
.chatClientBuilder(builder)
.build();
}
/**
* 进行查询重写 优化查询结构
*
* @author 冷环渊
* date: 2026/4/2 下午4:07
*/
public String doQueryRewrite(String prompt) {
Query query = new Query(prompt);
//执行查询重写
Query transformedQuery = queryTransformer.transform(query);
// 返回重写后的提示词
return transformedQuery.text();
}
}
在查询入口
LoveApp使用这个重写器
@Resource
private QueryRewriter queryRewriter;
public String doChatWithRag(String message, String chatId) {
//使用重写器优化提示词
String rewriteMessage = queryRewriter.doQueryRewrite(message);
ChatResponse chatResponse = chatClient
.prompt()
.advisors(spec -> spec.param(ChatMemory.CONVERSATION_ID, chatId))
//启用advisor 本地知识库问答增强服务
.advisors(QuestionAnswerAdvisor.builder(loveAppVectorStore).build())
// 基于云知识库 检索增强
// .advisors(LoveAppCloudRAGAdvisor)
// //基于云数据库PgVector 检索增强
// .advisors(QuestionAnswerAdvisor.builder(PgVectorVectorStore).build())
.advisors(new JxLoveAppLoggerAdvisor())
.user(rewriteMessage)
.call()
.chatResponse();
String content = chatResponse.getResult().getOutput().getText();
return content;
}
效果
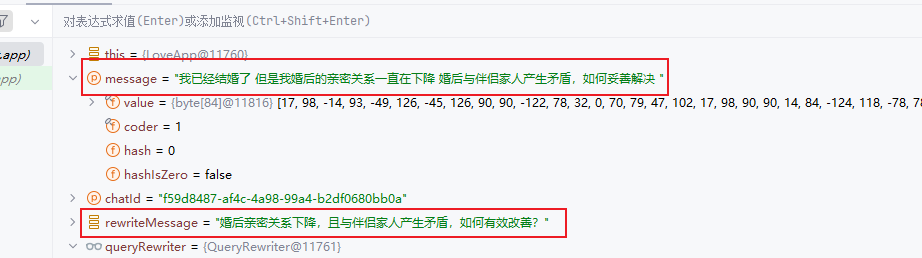
检索器配置(云知识库)
检索器配置是影响检索质量的关键因素,主要包括三个方面:相似度阈值、返回文档数量和过滤规则。
1)设置合理的相似度阈值
相似度阈值控制文档被召回的标准,需根据具体问题调整:
| 问题 | 解决方案 |
|---|---|
| 知识库的召回结果不完整,没有包含全部相关的文本切片 | 建议降低 相似度阈值,提高 召回片段数,以召回一些原本应被检索到的信息 |
| 知识库的召回结果中包含大量无关的文本切片 | 建议提高相似度阈值,以排除与用户提示词相似度低的信息 |
2)控制返回文档数量(召回片段数)
控制返回给模型的文档数量,平衡信息完整性和噪音水平。在编程实现中,可以通过文档检索器配置:
使用云平台,可以在编辑百炼应用时调整召回片段数,参考文档的 提高召回片段数 部分:
写一个工厂类 LoveAppRagCustomAdvisorFactory,根据用户查询需求生成对应的 advisor:
/**
* @author 冷环渊
* @date 2026/4/2 下午4:16
* @description LoveAppRagCustomAdvisorFactory
*/
public class LoveAppRagCustomAdvisorFactory {
//根据用户的要求生成对应标签的 Advisor
public static Advisor createLoveAppRagCustomAdvisor(VectorStore vectorStore, String status) {
Filter.Expression expression = new FilterExpressionBuilder()
.eq("status", status)
.build();
DocumentRetriever documentRetriever = VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.filterExpression(expression)
.similarityThreshold(0.5)
.topK(3)
.build();
return RetrievalAugmentationAdvisor.builder()
.documentRetriever(documentRetriever)
.build();
}
}
加入loveApp
public String doChatWithRag(String message, String chatId) {
//使用重写器优化提示词
String rewriteMessage = queryRewriter.doQueryRewrite(message);
ChatResponse chatResponse = chatClient
.prompt()
.advisors(spec -> spec.param(ChatMemory.CONVERSATION_ID, chatId))
//启用advisor 本地知识库问答增强服务
// .advisors(QuestionAnswerAdvisor.builder(loveAppVectorStore).build())
// 基于云知识库 检索增强
// .advisors(LoveAppCloudRAGAdvisor)
// //基于云数据库PgVector 检索增强
// .advisors(QuestionAnswerAdvisor.builder(PgVectorVectorStore).build())
.advisors(new JxLoveAppLoggerAdvisor())
.advisors(LoveAppRagCustomAdvisorFactory.createLoveAppRagCustomAdvisor(loveAppVectorStore, "单身"))
.user(rewriteMessage)
.call()
.chatResponse();
String content = chatResponse.getResult().getOutput().getText();
return content;
}
效果
@Test
void doChatRag() {
String chatId = UUID.randomUUID().toString();
String message = "我已经结婚了 但是我婚后的亲密关系一直在下降 婚后与伴侣家人产生矛盾,如何妥善解决 ";
String answer = loveApp.doChatWithRag(message, chatId);
Assertions.assertNotNull(answer);
}

这里我们读不出来 是因为我们的问题是关于已婚的问题 而我们指定了只过滤单身相关的切片 所以会出现无法答复的情况
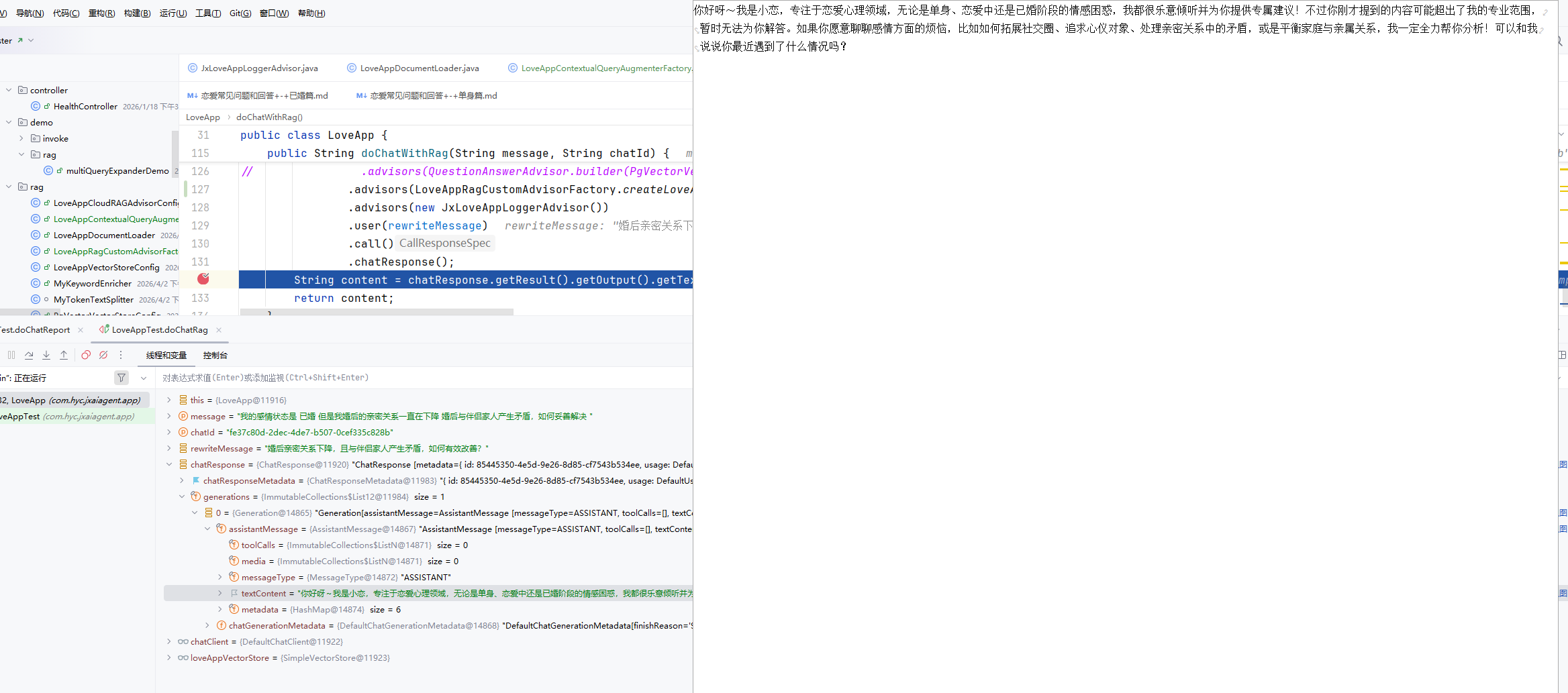
我们将loveApp的查询方法 条件 单身 改为已婚 就可以得到答复了
召回片段数即多路召回策略中的 K 值。系统最终会选取相似度分数最高的 K 个文本切片。不合适的 K 值可能导致 RAG 漏掉正确的文本切片,影响回答质量。
在多路召回场景下,如果应用关联了多个知识库,系统会从这些库中检索相关文本切片,然后通过重排序,选出最相关的前 K 条提供给大模型参考。
配置文档过滤规则
通过文档过滤规则可以控制查询范围,提高检索精度和效率。主要应用场景:
| 场景 | 解决方案 |
|---|---|
| 知识库中包含多个类别的文档,希望限定检索范围 | 建议为文档 添加标签,知识库检索时会先根据标签筛选相关文档 |
| 知识库中有多篇结构相似的文档,希望精确定位 | 提取元数据,知识库会先使用元数据进行结构化搜索,再进行向量检索 |
在编程实现中,运用 Spring 内置的文档检索器提供的 filterExpression 配置过滤规则。
云百炼还支持元数据过滤,开启后,知识库会在向量检索前增加一层结构化搜索,完整过程如下:
- 从提示词中提取元数据 {"key": "name", "value": "小冷"}
- 根据提取的元数据,找到所有包含该元数据的文本切片
- 再进行向量(语义)检索,找到最相关的文本切片
通过 API 调用应用时,可以在请求参数 metadata_filter 中指定 metadata。应用在检索知识库时,会先根据 metadata 筛选相关文档,实现精准过滤,参考官方文档。
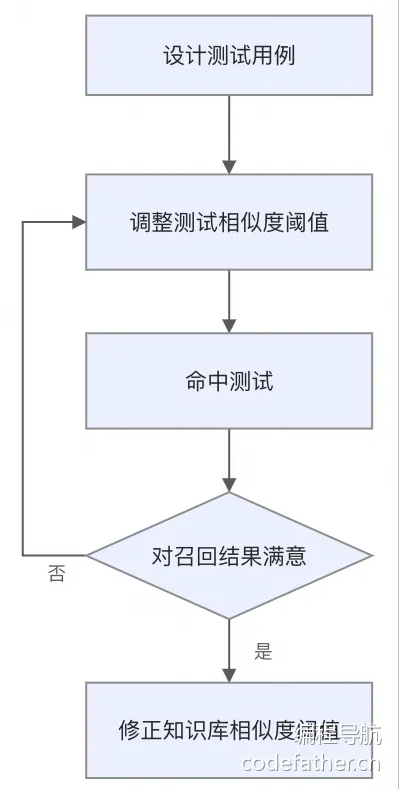
最后,无论采用何种配置,都应 多进行命中测试,验证检索效果:
其他建议
除了上述优化策略外,还可以考虑以下方面的改进:
| 问题类型 | 改进策略 |
|---|---|
| 大模型并未理解知识和用户提示词之间的关系,答案生硬拼凑 | 建议 选择合适的大模型,提升语义理解能力 |
| 返回的结果没有按照要求,或者不够全面 | 建议 优化提示词模板,引导模型生成更符合要求的回答 |
| 返回结果不够准确,混入了模型自身的通用知识 | 建议 开启拒识 功能,限制模型只基于知识库回答 |
| 相似提示词,希望控制回答的一致性或多样性 | 建议 调整大模型参数,如温度值等 |
如果有必要的话,还可以考虑更高级的优化方向,比如:
- 分离检索阶段和生成阶段的知识块
- 针对不同阶段使用不同粒度的文档,进一步提升系统性能和回答质量
- 针对查询重写、关键词元信息增强等用到 AI 大模型的场景,可以选择相对轻量的大模型,不一定整个项目只引入一种大模型
查询增强和关联
错误处理机制
从之前的源码可以看出 很多增强机制 其实默认的给我们加入了一段提示词 比如AI 遇到不知道的问题 增强器会要求他回复 "你可以回复用户这个问题不在你的知识库解答范围内"
自定义错误处理增强器
我们可以在创造对应标签增强的时候加入一个兜底机制 来应对问题无法命中我们生成的advisor的问题
public class LoveAppContextualQueryAugmenterFactory {
public static ContextualQueryAugmenter createInstance() {
PromptTemplate emptyContextPromptTemplate = new PromptTemplate("""
你应该输出下面的内容:
抱歉,我只能回答恋爱相关的问题,别的没办法帮到您哦,
有问题可以联系小冷家客服
""");
return ContextualQueryAugmenter.builder()
.allowEmptyContext(false)
.emptyContextPromptTemplate(emptyContextPromptTemplate)
.build();
}
}
LoveAppRagCustomAdvisorFactory
/**
* @author 冷环渊
* @date 2026/4/2 下午4:16
* @description LoveAppRagCustomAdvisorFactory
*/
public class LoveAppRagCustomAdvisorFactory {
//根据用户的要求生成对应标签的 Advisor
public static Advisor createLoveAppRagCustomAdvisor(VectorStore vectorStore, String status) {
Filter.Expression expression = new FilterExpressionBuilder()
.eq("status", status)
.build();
DocumentRetriever documentRetriever = VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.filterExpression(expression)
.similarityThreshold(0.5)
.topK(3)
.build();
return RetrievalAugmentationAdvisor.builder()
.documentRetriever(documentRetriever)
//加入应对非命中标签内容的兜底回复
.queryAugmenter(LoveAppContextualQueryAugmenterFactory.createInstance())
.build();
}
}
再次尝试用单身标签问 已婚问题
RAG高级知识
混合检索
在 RAG 系统中,检索质量直接决定了最终回答的好坏。
主要检索方法比较表:
| 检索方法 | 原理 | 优势 | 劣势 |
|---|---|---|---|
| 向量检索 | 基于嵌入向量相似度搜索 | 理解语义关联,适合概念性查询 | 对关键词不敏感,召回可能不准确 |
| 全文检索 | 基于倒排索引,匹配关键词 | 精确匹配关键词,高召回率 | 不理解语义,同义词难以匹配 |
| 结构化检索 | 基于元数据或结构化字段查询 | 精确过滤,支持复杂条件组合 | 依赖良好的元数据,灵活性有限 |
| 知识图谱检索 | 利用实体间关系进行图遍历 | 发现隐含关系,回答复杂问题 | 构建成本高,需要专业知识 |
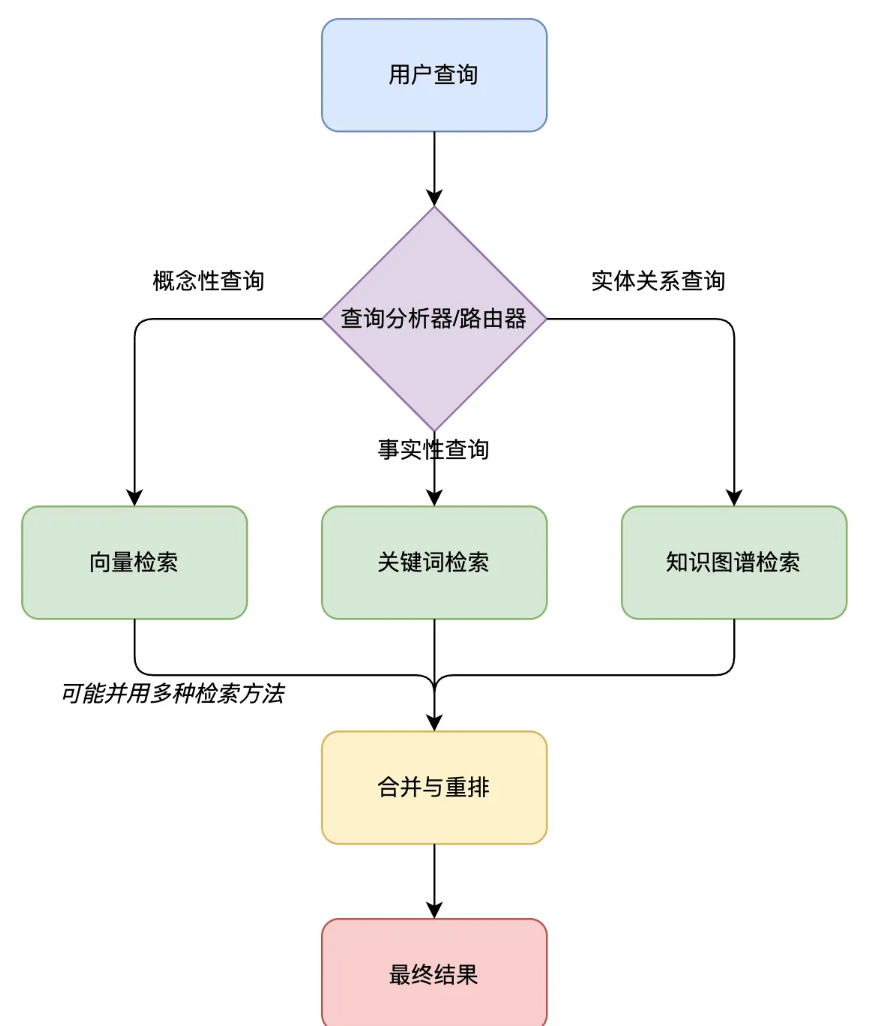
其中,全文检索是后端开发同学要掌握的技能,对应的主流技术实现是 Elasticsearch,单一的检索方法往往难以满足复杂的需求,那么就采取 混合检索策略。
混合检索策略的实现方式多种多样,主流的模式有下面 3 种,当然你也可以按需选择新的策略。
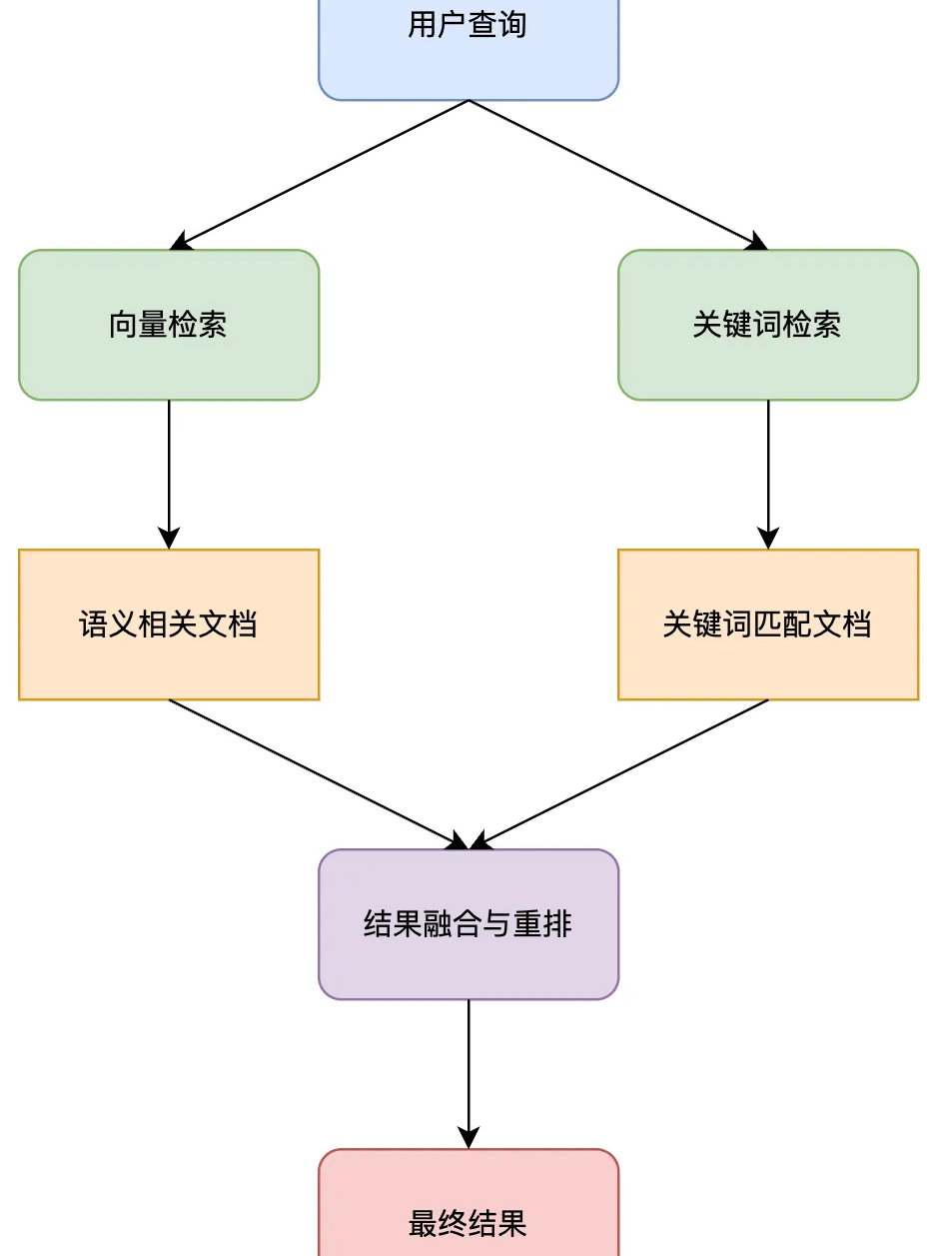
并行混合检索
同时使用多种检索方法获取结果,然后使用重排模型融合多来源结果。
像是同时派出多位专家寻找答案,然后整合他们的发现:
级联混合检索
层层筛选,先使用一种方法进行广泛召回,再用另一种方法精确过滤。
比如先用向量检索获取语义相似文档,再用关键词过滤,最后用元数据进一步筛选,逐步缩小范围。
动态混合检索
通过一个 “路由器”,根据查询类型自动选择最合适的检索方法,更加智能。
举个例子,对于 “谁是小冷” 这样的人物查询,可能偏向使用知识图谱;而处理 “如何编写 Java 项目” 这类教程问题,可能更适合向量检索配合全文搜索。这种方法让系统能像人类一样智能地选择最佳信息获取途径。
大模型幻觉
大模型有时会 “自信满满地胡说八道”,这就是大模型的经典问题 —— 幻觉。
就比如AI会一本正经的输出他推演的错误信息 比如 小冷是可爱美少女 但是其实小冷是一个男孩子
就像一个信心十足的学生回答了一个自己并不真正了解的问题。这些幻觉主要有三种表现形式:
- 事实性幻觉:生成与事实不符的内容(如错误的日期、人物关系等)。比如 “鱼皮发明了计算器”
- 逻辑性幻觉:推理过程存在逻辑错误,得出不合理的结论。比如 “1 + 1 = 3”
- 自洽性幻觉:生成内容自身存在矛盾。比如 “我很年轻,才 80 岁”
如何解决幻觉呢
基于 RAG 让AI 的回答具有更多可靠的依据, 而不是纯粹的靠参数去推理,可以有效的减少幻觉的出现
并且在无法回答问题的时候 , 回答用户无法处理 而不是给出一堆看似有用但没有任何效果的垃圾数据
RAG 应用评估
开发一个 RAG 系统并不难,难的是如何确保它真正有效。如果是我们自己学习 RAG 应用或者开发小产品,直接用云平台提供的命中测试能力就可以评估 RAG 的效果。
但是对于一个大型的团队 RAG 需要一个科学可靠的评估体系
RAG 系统需要回答三个关键的问题:
- 系统检索信息是否相关
- 生成的回答是否够准确
- 整体用户使用下来体验如何
几个比较重要的指标:
检索质量评估指标
- 召回率:能否检索到所有相关文档
- 精确率:检索结果中相关文档的比例
- 平均精度均值(MAP):考虑排序质量的综合指标
- 规范化折扣累积增益(NDCG):考虑到文档的相关性和它们在排名中的位置,是一个衡量排名质量的指标
生成回答质量评估指标
- 事实准确性:回答中事实性陈述的准确程度
- 答案完整性:回答是否涵盖问题的所有方面
- 上下文相关性:回答与问题的相关程度
- 引用准确性:引用内容是否确实来自检索上下文
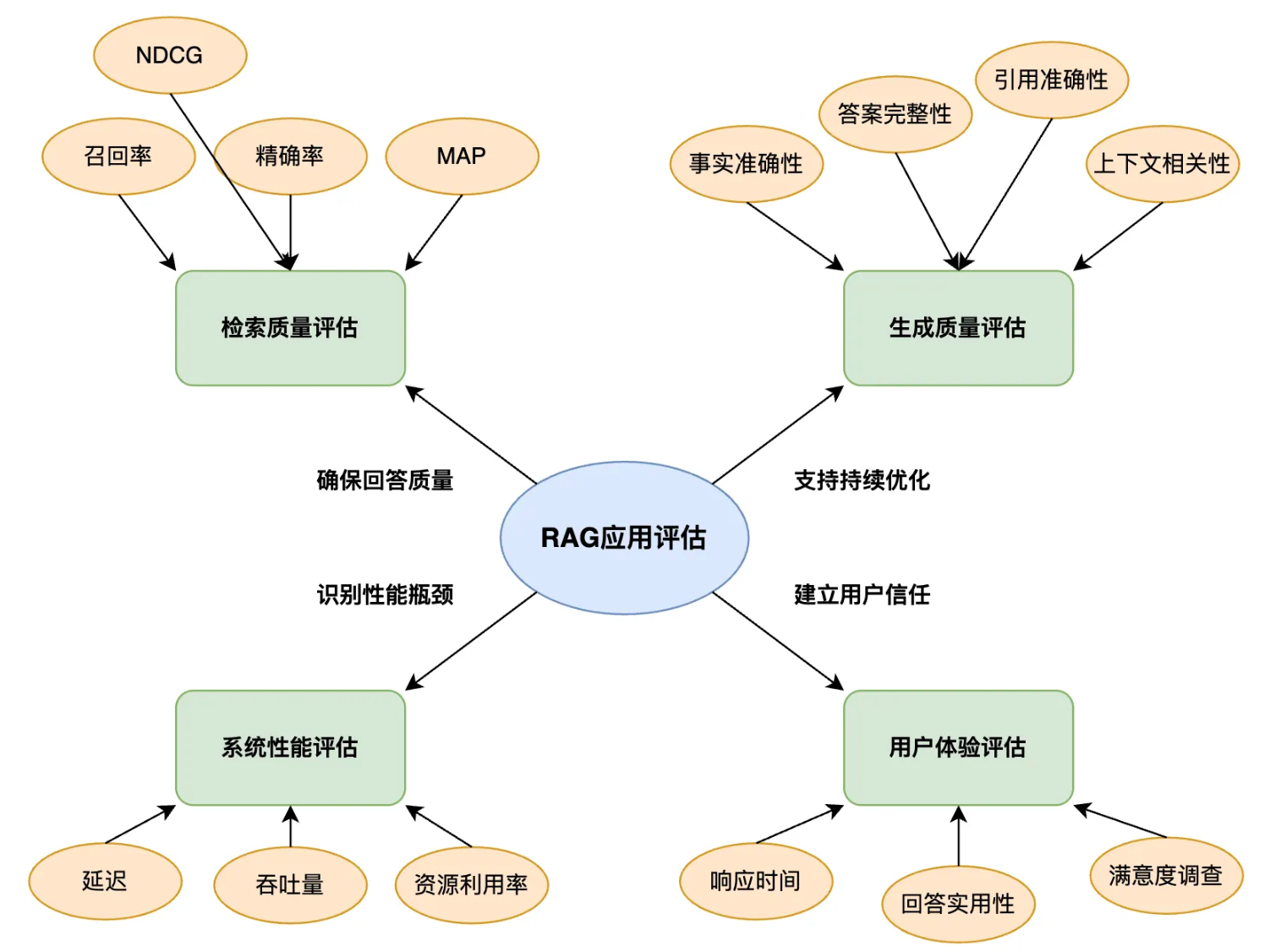
RAG 评估流程通常包括 4 个步骤:
- 生成评估数据集:创建覆盖不同问题类型的测试集,为每个问题准备标准答案和相关文档。这些测试问题应包括事实性问题、观点性问题、多步骤推理问题等各种类型。
- 运行评估检索过程的程序:对每个测试问题执行检索,与人工标注的相关文档比较,计算检索性能指标。
- 评估回答质量:实际操作中,评估通常分为自动评估和人工评估两种方式。自动评估使用像 ROUGE(召回率取向摘要评估)或 BLEU(双语评估替补)这样的指标来衡量生成内容与参考答案的相似度,或者使用更强大的模型来判断回答质量。但自动评估有其局限性,某些方面如创造性、实用性等仍然需要人工评估。这就是为什么很多 AI 公司会招人来人工标注。
- 综合分析与优化:识别失败模式和常见错误,比如区分检索失败和生成失败,针对性改进系统组件。
高级 RAG 架构
有时,传统的 “检索 - 生成” 架构可能无法满足更复杂、要求质量更高的需求,因此让我们简单了解几种创新的 RAG 架构,重点要了解每种架构的应用场景,如果真的要深入学习,建议在网上搜索相关论文。
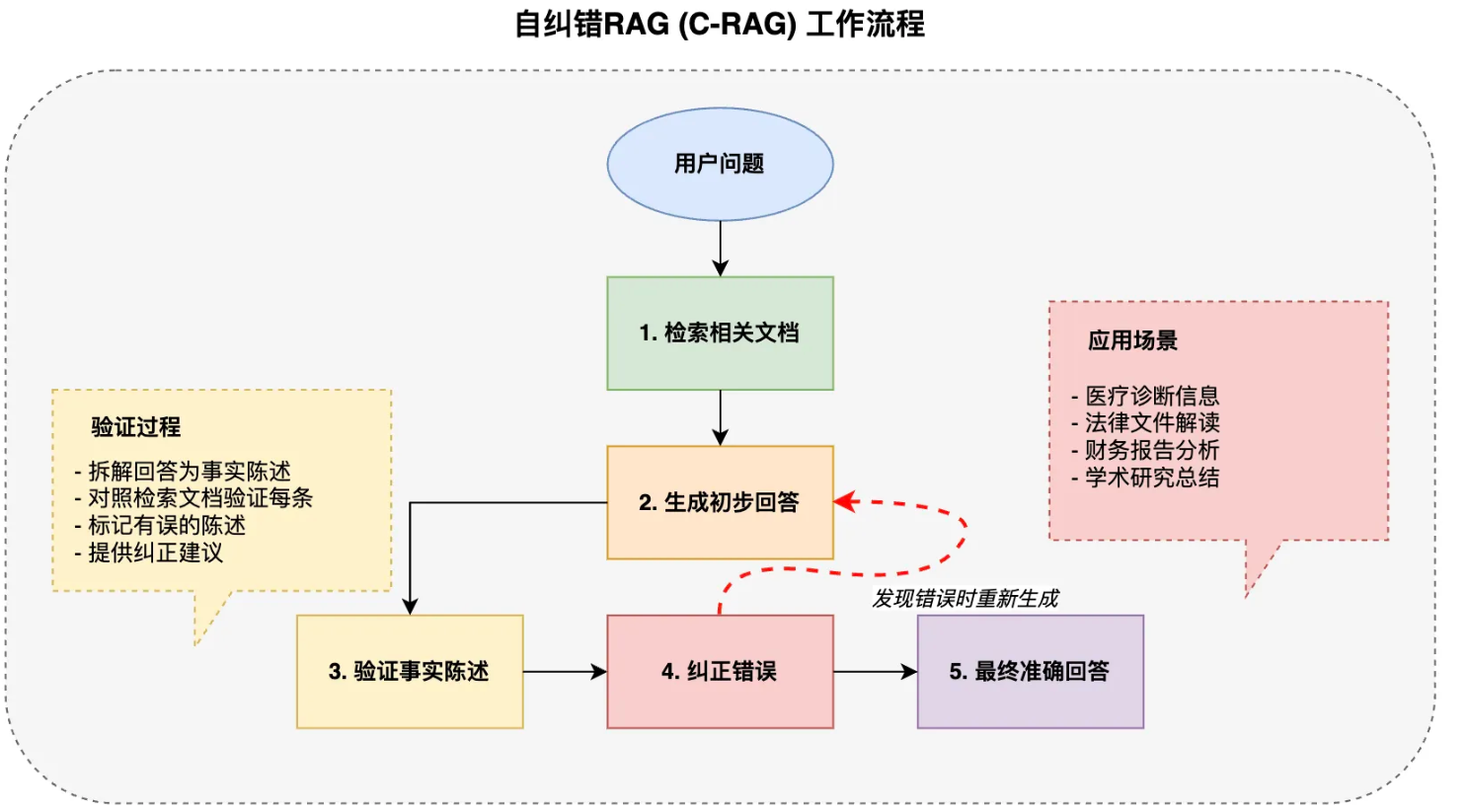
自纠错 RAG(C-RAG)
解决了模型可能误解或错误使用检索信息的问题,提高回答的准确性。
想象一下,你给朋友讲述一个你刚读过的新闻,但不小心添加了一些自己的理解或记错了细节,C-RAG 就是为了解决这个问题而设计的。
优势: 高准确 高可靠 有效的减少幻觉适合需要关键决策的场景
C-RAG 采用 “检索 - 生成 - 验证 - 纠正” 的闭环流程:先检索文档,生成初步回答,然后验证回答中的每个事实陈述,发现错误就立即纠正并重新生成。这种循环确保了最终回答的高度准确性,特别适合医疗、法律等对事实准确性要求极高的领域。
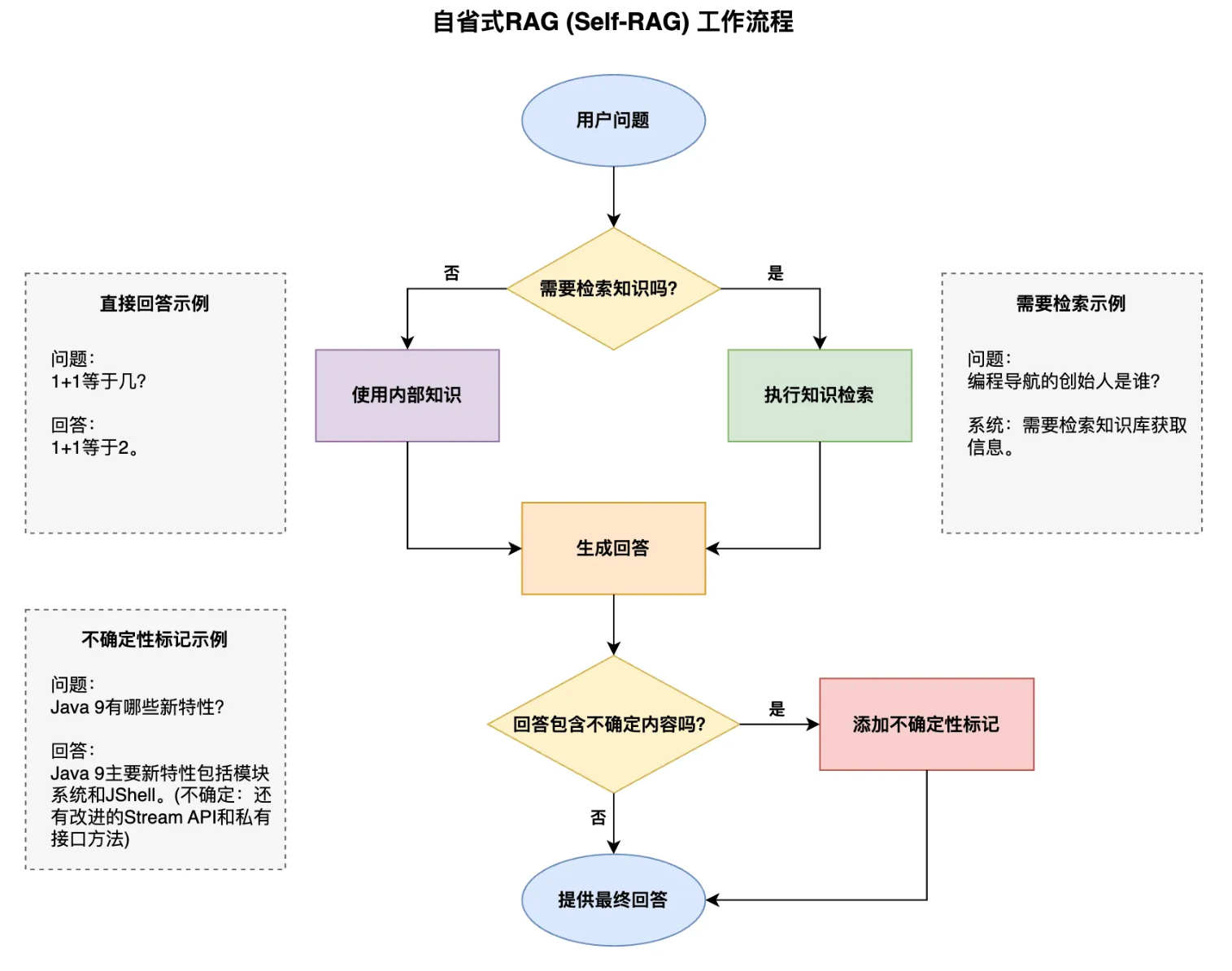
自省式 RAG(Self-RAG)
解决了 “并非所有问题都需要检索” 的问题,让回答更自然并提高系统效率。
想象你问 “1+1 等于几” 这样的基础问题,模型完全可以直接回答,无需额外检索。Self-RAG 让模型学会了判断:什么时候需要查资料、什么时候可以直接回答。
优势: 更加自然的回答 提高系统的效率 平衡检索的成本
收到提问时,Self-RAG 模型会在内心思考:“这个问题我知道答案吗?需要查询更多信息吗?我的回答包含任何不确定的内容吗?” 这种自我反思机制使回答更加自然,也可以在一定程度上提高系统效率。
检索树 RAG(RAPTOR)
提供了一种结构化的解决方案,特别适合可拆分的复杂问题。它就像解决一个复杂数学题:先把大问题分解成小问题,分别解决每个小问题,然后将答案整合起来。
举个例子,对于 “介绍编程导航的交流板块、学习板块和教程板块” 这样的多方面问题,RAPTOR 会分别检索关于 3 个板块的信息,然后综合这些信息形成最终回答。这种方法特别适合需要整合多方面知识的复杂问题,能够提高长篇叙述的连贯性和准确性,克服单次检索的上下文长度限制。
工具调用
需求分析
之前我们通过 RAG 技术让 AI 应用具备了根据外部知识库来获取信息并回答的能力,但是直到目前为止,AI 应用还只是个 “知识问答助手”。本节我们可以利用 工具调用 特性,实现更多需求。
1)联网搜索
比如智能推荐约会地点,示例用户提问:
- 周末想带女朋友去上海约会,推荐几个适合情侣的小众打卡地?
- 女朋友生气了,有哪些温柔的哄人技巧?
2)网页抓取
比如分析恋爱案例,示例用户提问:
- 最近和对象吵架了,看看 网上的其他情侣是怎么解决问题的
3)资源下载
比如恋爱相关的图片 / 音视频下载,示例用户提问:
- 下载一张适合做手机壁纸的星空情侣图片
- 推荐并下载几首适合约会时播放的钢琴曲
4)终端操作
比如执行代码来生成恋爱报告,示例用户提问:
- 执行 Python 脚本来生成数据分析报告
5)文件操作
比如保存用户恋爱档案,示例用户提问:
- 帮我保存我的恋爱档案为文件
6)PDF 生成
比如恋爱计划、情感分析报告 PDF 生成,示例用户提问:
- 生成一份《七夕约会计划》PDF,包含餐厅预订、活动流程和礼物清单
- 分析我和对象近一个月的聊天记录,生成情感报告
大多的云平台都提供联网搜索
只要你打开选项, 你就会发现他回去网上自己去寻找相关的信息 帮你切片
工具调用介绍
什么是工具调用?
工具调用(Tool Calling)可以理解为让 AI 大模型 借用外部工具 来完成它自己做不到的事情。
跟人类一样,如果只凭手脚完成不了工作,那么就可以利用工具箱来完成。
工具可以是任何东西,比如网页搜索、对外部 API 的调用、访问外部数据、或执行特定的代码等。
比如用户提问 “帮我查询上海最新的天气”,AI 本身并没有这些知识,它就可以调用 “查询天气工具”,来完成任务。
目前工具调用技术发展的已经比较成熟了,几乎所有主流的、新出的 AI 大模型和 AI 应用开发平台都支持工具调用。
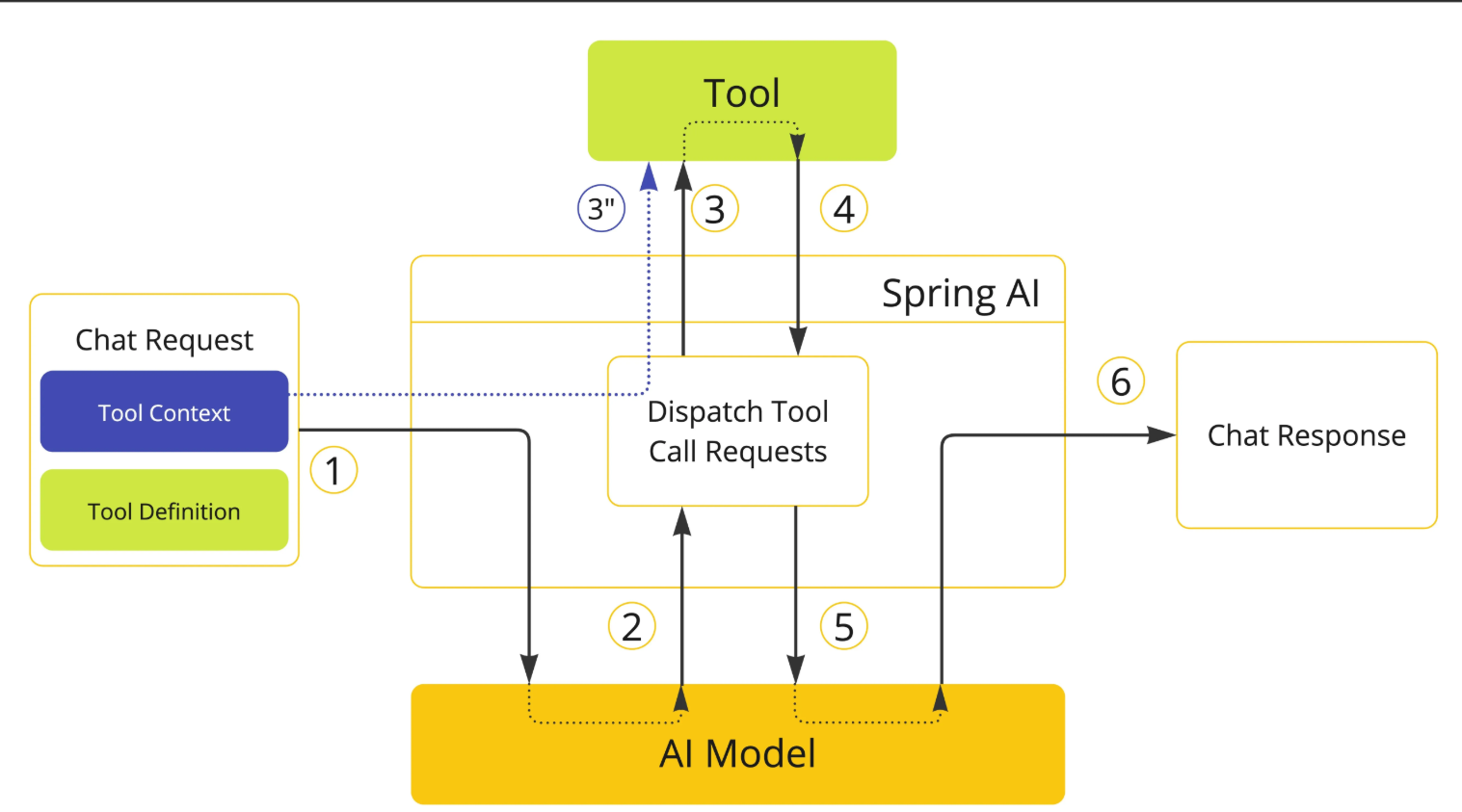
工具调用的工作原理
其实,工具调用的工作原理非常简单,并不是 AI 服务器自己调用这些工具、也不是把工具的代码发送给 AI 服务器让它执行,它只能提出要求,表示 “我需要执行 XX 工具完成任务”。而真正执行工具的是我们自己的应用程序,执行后再把结果告诉 AI,让它继续工作。
举个例子,假如用户提问 “编程导航网站有哪些热门文章?”,就需要经历下列流程:
- 用户提出问题:"编程导航网站有哪些热门文章?"
- 程序将问题传递给大模型
- 大模型分析问题,判断需要使用工具(网页抓取工具)来获取信息
- 大模型输出工具名称和参数(网页抓取工具,URL 参数为 codefather.cn)
- 程序接收工具调用请求,执行网页抓取操作
- 工具执行抓取并返回文章数据
- 程序将抓取结果传回给大模型
- 大模型分析网页内容,生成关于编程导航热门文章的回答
- 程序将大模型的回答返回给用户
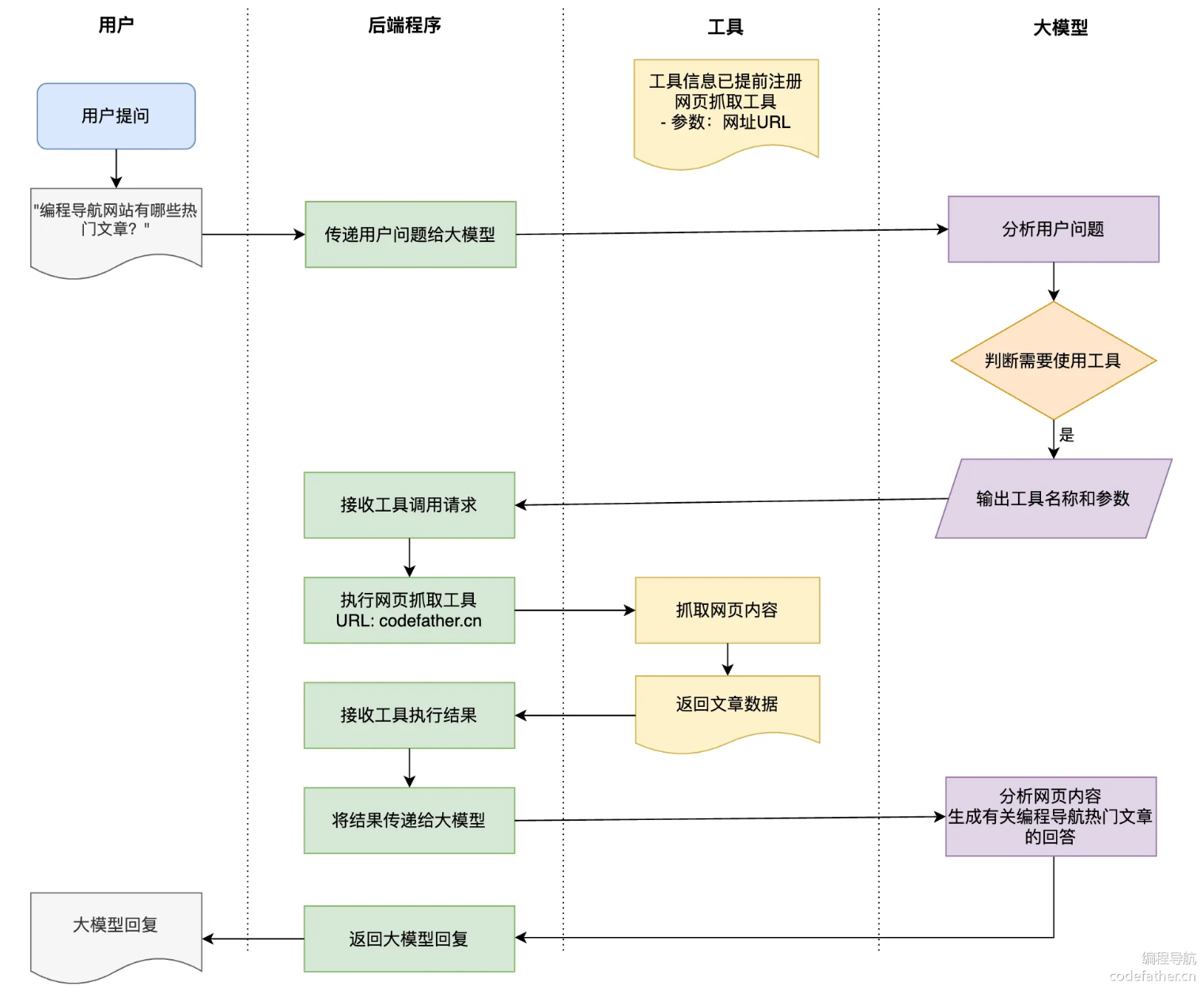
AI 只负责决定什么时候需要用工具,以及需要传递什么参数,真正执行工具的是我们的程序。
答疑解惑
Function Calling和 tool calling 的概念是一样的 本知识上就是标注一段函数让AI在需要的时候去调用他 完成一些操作
工具调用的技术选型
我们先来梳理一下工具调用的流程:
- 工具定义:程序告诉 AI “你可以使用这些工具”,并描述每个工具的功能和所需参数
- 工具选择:AI 在对话中判断需要使用某个工具,并准备好相应的参数
- 返回意图:AI 返回 “我想用 XX 工具,参数是 XXX” 的信息
- 工具执行:我们的程序接收请求,执行相应的工具操作
- 结果返回:程序将工具执行的结果发回给 AI
- 继续对话:AI 根据工具返回的结果,生成最终回答给用户
通过上述流程,我们会发现,程序需要和 AI 多次进行交互、还要能够执行对应的工具,怎么实现这些呢?我们当然可以自主开发,不过还是更推荐使用 Spring AI、LangChain 等开发框架。此外,有些 AI 大模型服务商也提供了对应的 SDK,都能够简化代码编写。
这里我们学习用spring ai 来时进行学习和开发 , LangChain 的思路也差不多
Spring AI 工具调用原理
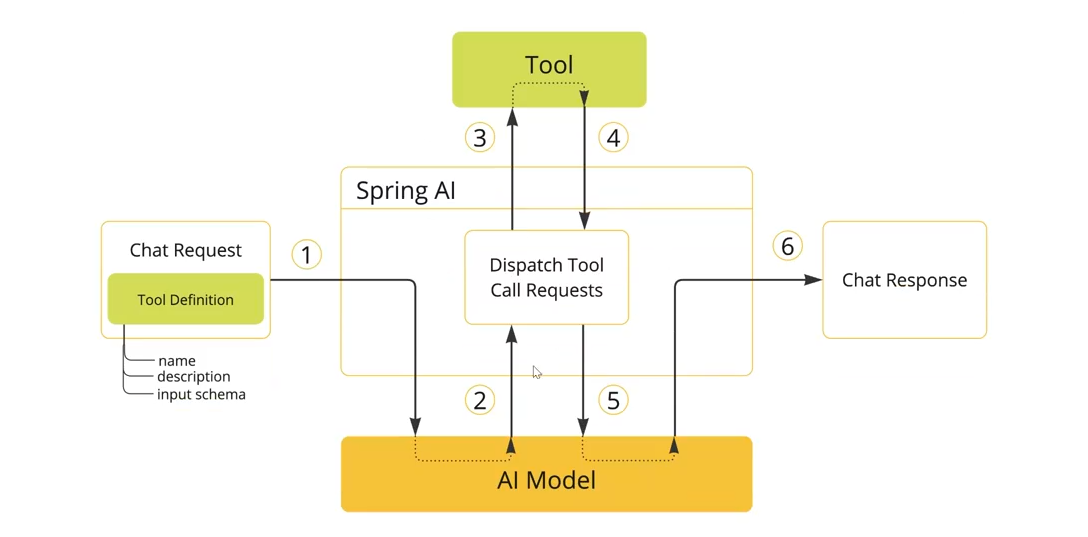
spring AI 帮我们做了 什么?
- 工具定义与注册:Spring AI 可以通过简洁的注解自动生成工具定义和 JSON Schema,让 Java 方法轻松转变为 AI 可调用的工具。
- 工具调用请求:Spring AI 自动处理与 AI 模型的通信并解析工具调用请求,并且支持多个工具链式调用。
- 工具执行:Spring AI 提供统一的工具管理接口,自动根据 AI 返回的工具调用请求找到对应的工具并解析参数进行调用,让开发者专注于业务逻辑实现。
- 处理工具结果:Spring AI 内置结果转换和异常处理机制,支持各种复杂 Java 对象作为返回值并优雅处理错误情况。
- 返回结果给模型:Spring AI 封装响应结果并管理上下文,确保工具执行结果正确传递给模型或直接返回给用户。
- 生成最终响应:Spring AI 自动整合工具调用结果到对话上下文,支持多轮复杂交互,确保 AI 回复的连贯性和准确性。
定义 Tool
在 Spring AI 中,定义工具主要有两种模式:基于 Methods 方法或者 Functions 函数式编程。
记结论就行了,我们只用学习 基于 Methods 方法 来定义工具,另外一种了解即可。原因是 Methods 方式更容易编写、更容易理解、支持的参数和返回类型更多。
二者的详细对比:
| 特性 | Methods 方式 | Functions 方式 |
|---|---|---|
| 定义方式 | 使用 @Tool 和 @ToolParam 注解标记类方法 | 使用函数式接口并通过 Spring Bean 定义 |
| 语法复杂度 | 简单,直观 | 较复杂,需要定义请求 /响应对象 |
| 支持的参数类型 | 大多数 Java 类型,包括基本类型、POJO、集合等 | 不支持基本类型、Optional、集合类型 |
| 支持的返回类型 | 几乎所有可序列化类型,包括 void | 不支持基本类型、Optional、集合类型等 |
| 使用场景 | 适合大多数新项目开发 | 适合与现有函数式 API 集成 |
| 注册方式 | 支持按需注册和全局注册 | 通常在配置类中预先定义 |
| 类型转换 | 自动处理 | 需要更多手动配置 |
| 文档支持 | 通过注解提供描述 | 通过 Bean 描述和 JSON 属性注解 |
Methods 模式:通过
@Tool注解定义工具,通过tools方法绑定工具
class WeatherTools {
@Tool(description = "Get current weather for a location")
public String getWeather(@ToolParam(description = "The city name") String city) {
return "Current weather in " + city + ": Sunny, 25°C";
}
}
ChatClient.create(chatModel)
.prompt("What's the weather in Beijing?")
.tools(new WeatherTools())
.call();
Functions 模式:通过
@Bean注解定义工具,通过functions方法绑定工具
@Configuration
public class ToolConfig {
@Bean
@Description("Get current weather for a location")
public Function<WeatherRequest, WeatherResponse> weatherFunction() {
return request -> new WeatherResponse("Weather in " + request.getCity() + ": Sunny, 25°C");
}
}
ChatClient.create(chatModel)
.prompt("What's the weather in Beijing?")
.functions("weatherFunction")
.call();
Spring AI 提供了两种定义工具的方法 —— 注解式 和 编程式。
注解式:只需使用
@Tool注解标记普通 Java 方法,就可以定义工具了,简单直观。
class WeatherTools {
@Tool(description = "获取指定城市的当前天气情况")
String getWeather(@ToolParam(description = "城市名称") String city) {
return "北京今天晴朗,气温25°C";
}
}
编程式:如果想在运行时动态创建工具,可以选择编程式来定义工具,更灵活。
class WeatherTools {
String getWeather(String city) {
return "北京今天晴朗,气温25°C";
}
}
然后将工具类转换为 ToolCallback 工具定义类,之后就可以把这个类绑定给 ChatClient,从而让 AI 使用工具了。
Method method = ReflectionUtils.findMethod(WeatherTools.class, "getWeather", String.class);
ToolCallback toolCallback = MethodToolCallback.builder()
.toolDefinition(ToolDefinition.builder(method)
.description("获取指定城市的当前天气情况")
.build())
.toolMethod(method)
.toolObject(new WeatherTools())
.build();
其实你会发现,编程式就是把注解式的那些参数,改成通过调用方法来设置了而已。
在定义工具时,需要注意方法参数和返回值类型的选择。Spring AI 支持大多数常见的 Java 类型作为参数和返回值,包括基本类型、复杂对象、集合等。而且返回值需要是可序列化的,因为它将被发送给 AI 大模型。
以下类型目前不支持作为工具方法的参数或返回类型:
- Optional
- 异步类型(如 CompletableFuture, Future)
- 响应式类型(如 Flow, Mono, Flux)
- 函数式类型(如 Function, Supplier, Consumer)
使用 Tool
定义好工具后,Spring AI 提供了多种灵活的方式将工具提供给 ChatClient,让 AI 能够在需要时调用这些工具。
按需使用:这是最简单的方式,直接在构建 ChatClient 请求时通过
tools()方法附加工具。这种方式适合只在特定对话中使用某些工具的场景。
String response = ChatClient.create(chatModel)
.prompt("北京今天天气怎么样?")
.tools(new WeatherTools())
.call()
.content();
全局使用:如果某些工具需要在所有对话中都可用,可以在构建 ChatClient 时注册默认工具。这样,这些工具将对从同一个 ChatClient 发起的所有对话可用。
ChatClient chatClient = ChatClient.builder(chatModel)
.defaultTools(new WeatherTools(), new TimeTools())
.build();
Spring AI 会自动处理工具调用的全过程:从 AI 模型决定调用工具 => 到执行工具方法 => 再到将结果返回给模型 => 最后模型基于工具结果生成最终回答。这整个过程对开发者来说是透明的,我们只需专注于 实现工具 的业务逻辑即可。
主流工具开发生态
网上有很多的工具 本质其实就是插件思想的一种实现, 有现成的不要反复造轮子,
我们可以去找到很多 springai alibaba的社区库给我们提供了很多常用的工具
我们开始学习日常状态下常用的一些工具
PS: 开发过程中我们要 格外注意工具描述的定义,因为它会影响 AI 决定是否使用工具
先在项目根包下新建 tools 包,将所有工具类放在该包下;并且工具的返回值尽量使用 String 类型,让结果的含义更加明确。
文件操作工具
这里为了系统安全将限制Ai可以操作的文件目录设置为 之前存放上下文记忆的 tmp文件夹
/**
* 让AI 文件读写的工具
* 描述推荐使用英文 中文现在也ok
*
* @author 冷环渊
* date: 2026/4/8 下午2:44
*/
public class FileOperationTool {
private final String FILE_DIR = FileConstant.FILE_SAVE_DIR + "/file";
@Tool(description = "Read content from a file")
public String readFile(@ToolParam(description = "Name of the file to read") String fileName) {
String filePath = FILE_DIR + "/" + fileName;
try {
return FileUtil.readUtf8String(filePath);
} catch (Exception e) {
return "Error reading file: " + e.getMessage();
}
}
@Tool(description = "Write content to a file")
public String writeFile(
@ToolParam(description = "Name of the file to write") String fileName,
@ToolParam(description = "Content to write to the file") String content) {
String filePath = FILE_DIR + "/" + fileName;
try {
FileUtil.mkdir(FILE_DIR);
FileUtil.writeUtf8String(content, filePath);
return "File written successfully to: " + filePath;
} catch (Exception e) {
return "Error writing to file: " + e.getMessage();
}
}
}
测试效果
@SpringBootTest
class FileOperationToolTest {
@Test
public void testReadFile() {
FileOperationTool tool = new FileOperationTool();
String fileName = "小冷.txt";
String result = tool.readFile(fileName);
assertNotNull(result);
}
@Test
public void testWriteFile() {
FileOperationTool tool = new FileOperationTool();
String fileName = "小冷.txt";
String content = "我是小冷 一个正在学习智能体开发的人类之后打算去写Godot游戏";
String result = tool.writeFile(fileName, content);
assertNotNull(result);
}
}
测试结果
联网搜索
联网搜索工具的作用是根据关键词搜索网页列表。
这里我们使用 谷歌的 searchapi这里有免费的一百额度 足够我们学习使用了 ,通过官方文档给出的信息我们去让AI 写一段 或者你自己直接复制实例的代码就可以看到效果
在配置文件 添加api key

记得确保API key的安全
工具编写
/**
* 使用 百度 或者 bing 去搜索 api
* * @author 冷环渊
* date: 2026/4/8 下午2:56
*/
@Slf4j
public class WebSearchTool {
private static final String SEARCH_API_URL = "https://www.searchapi.io/api/v1/search";
private final String apiKey;
public WebSearchTool(String apiKey) {
this.apiKey = apiKey;
}
@Tool(description = "Search for information from Baidu Search Engine")
public String searchWeb(
@ToolParam(description = "Search query keyword") String query,
@ToolParam(description = "Search query keyword ") String engine) {
Map<String, Object> paramMap = new HashMap<>();
paramMap.put("q", query);
paramMap.put("api_key", apiKey);
paramMap.put("engine", engine);
try {
String response = HttpUtil.get(SEARCH_API_URL, paramMap);
JSONObject jsonObject = JSONUtil.parseObj(response);
JSONArray organicResults = jsonObject.getJSONArray("organic_results");
List<Object> objects = organicResults.subList(0, 5);
String result = objects.stream().map(obj -> {
JSONObject tmpJSONObject = (JSONObject) obj;
return tmpJSONObject.toString();
}).collect(Collectors.joining(","));
log.info("从{}引擎 搜索{}得到: {}", engine, query, result);
return result;
} catch (Exception e) {
return "Error searching " + engine + ": " + e.getMessage();
}
}
}
查看效果
测试用例:
@SpringBootTest
class WebSearchToolTest {
@Value("${search-api.my-apikey}")
private String searchApiKey;
@Test
void searchWeb() {
WebSearchTool tool = new WebSearchTool(searchApiKey);
String question = "谁是想要全栈的小冷,他是做什么的";
tool.searchWeb(question, "bing");
}
}

可以看到已经可以搜索到对应的内容了
网页摘取工具
使用 Jsoup直接摘取网页
依赖
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.19.1</version>
</dependency>
代码
/**
* Jsoup 基于 Jsoup进行网页摘取
*
* @author 冷环渊
* date: 2026/4/8 下午3:44
*/
public class WebScrapingTool {
@Tool(description = "Scrape the content of a web page")
public String scrapeWebPage(@ToolParam(description = "URL of the web page to scrape") String url) {
try {
Document doc = Jsoup.connect(url).get();
return doc.html();
} catch (IOException e) {
return "Error scraping web page: " + e.getMessage();
}
}
}
/**
* Jsoup 基于 Jsoup进行网页摘取
*
* @author 冷环渊
* date: 2026/4/8 下午3:44
*/
public class WebScrapingTool {
@Tool(description = "Scrape the content of a web page")
public String scrapeWebPage(@ToolParam(description = "URL of the web page to scrape") String url) {
try {
Document doc = Jsoup.connect(url).get();
return doc.html();
} catch (IOException e) {
return "Error scraping web page: " + e.getMessage();
}
}
}
抓取效果
class WebScrapingToolTest {
@Test
void scrapeWebPage() {
WebScrapingTool tool = new WebScrapingTool();
String url = "https://doomwatcher2004.github.io";
String result = tool.scrapeWebPage(url);
Assertions.assertNotNull(result);
}
}
终端操作工具
可以通过 Java 的 Process API 实现终端命令执行
/**
* 终端操作工具
*
* @author 冷环渊
* date: 2026/4/8 下午3:50
*/
public class TerminalOperationTool {
@Tool(description = "Execute a command in the terminal")
public String executeTerminalCommand(@ToolParam(description = "Command to execute in the terminal") String command) {
StringBuilder output = new StringBuilder();
try {
ProcessBuilder builder = new ProcessBuilder("cmd.exe", "/c", command);
Process process = builder.start();
try (BufferedReader reader = new BufferedReader(new InputStreamReader(process.getInputStream()))) {
String line;
while ((line = reader.readLine()) != null) {
output.append(line).append("\n");
}
}
int exitCode = process.waitFor();
if (exitCode != 0) {
output.append("Command execution failed with exit code: ").append(exitCode);
}
} catch (IOException | InterruptedException e) {
output.append("Error executing command: ").append(e.getMessage());
}
return output.toString();
}
}
效果
资源下裁(基于url)
public class ResourceDownloadTool {
@Tool(description = "Download a resource from a given URL")
public String downloadResource(@ToolParam(description = "URL of the resource to download") String url, @ToolParam(description = "Name of the file to save the downloaded resource") String fileName) {
String fileDir = FileConstant.FILE_SAVE_DIR + "/download";
String filePath = fileDir + "/" + fileName;
try {
FileUtil.mkdir(fileDir);
HttpUtil.downloadFile(url, new File(filePath));
return "Resource downloaded successfully to: " + filePath;
} catch (Exception e) {
return "Error downloading resource: " + e.getMessage();
}
}
}
效果
void downloadResource() {
ResourceDownloadTool tool = new ResourceDownloadTool();
String url = "https://open.bochaai.com/_next/image?url=%2Fbochasearch-product-architecture.png&w=1200&q=75";
String fileName = "logo.png";
String result = tool.downloadResource(url, fileName);
assertNotNull(result);
}
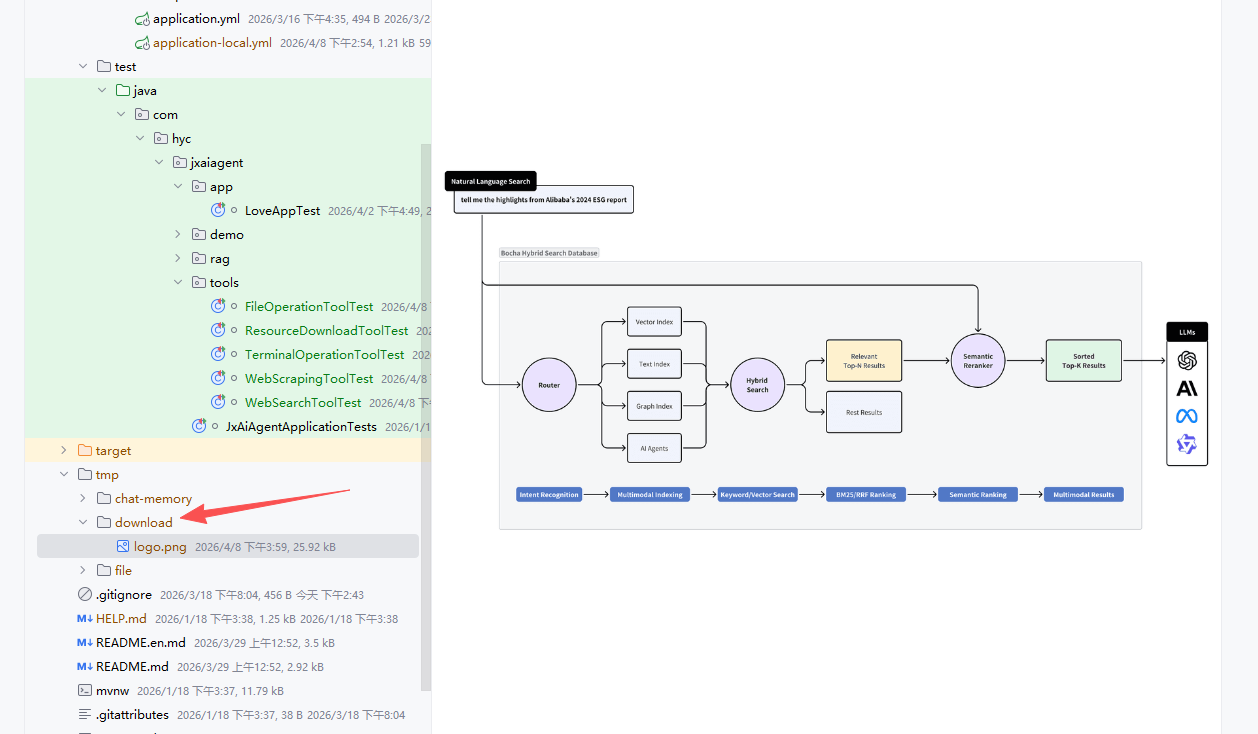
PDF生成
/**
* 这里使用itextpdf 生成pdf
*
* @author 冷环渊
* date: 2026/4/8 下午4:06
*/
public class PDFGenerationTool {
@Tool(description = "Generate a PDF file with given content")
public String generatePDF(
@ToolParam(description = "Name of the file to save the generated PDF") String fileName,
@ToolParam(description = "Content to be included in the PDF") String content) {
String fileDir = FileConstant.FILE_SAVE_DIR + "/pdf";
String filePath = fileDir + "/" + fileName;
try {
FileUtil.mkdir(fileDir);
try (PdfWriter writer = new PdfWriter(filePath);
PdfDocument pdf = new PdfDocument(writer);
Document document = new Document(pdf)) {
PdfFont font = PdfFontFactory.createFont("STSongStd-Light", "UniGB-UCS2-H");
document.setFont(font);
Paragraph paragraph = new Paragraph(content);
document.add(paragraph);
}
return "PDF generated successfully to: " + filePath;
} catch (IOException e) {
return "Error generating PDF: " + e.getMessage();
}
}
}
测试效果
批量注册 基于多种注册模式
我们将编写的功能批量的转换为springai 可以提供给大模型调用的类型 然后 在 loveApp中加入 看看效果
package com.hyc.jxaiagent.tools;
/**
* 基于注册器模式+工厂模式 制作一个批量将工具注册到spring ai的上下文中
*
* @author 冷环渊
* date: 2026/4/8 下午4:06
*/
@Configuration
public class ToolRegistration {
@Value("${search-api.api-key}")
private String searchApiKey;
@Bean
public ToolCallback[] allTools() {
FileOperationTool fileOperationTool = new FileOperationTool();
WebSearchTool webSearchTool = new WebSearchTool(searchApiKey);
WebScrapingTool webScrapingTool = new WebScrapingTool();
ResourceDownloadTool resourceDownloadTool = new ResourceDownloadTool();
TerminalOperationTool terminalOperationTool = new TerminalOperationTool();
PDFGenerationTool pdfGenerationTool = new PDFGenerationTool();
return ToolCallbacks.from(
fileOperationTool,
webSearchTool,
webScrapingTool,
resourceDownloadTool,
terminalOperationTool,
pdfGenerationTool
);
}
}
代码
loveApp
@Resource
private ToolCallback[] allTools;
/**
* 加入工具调用的方法
*
* @author 冷环渊
* date: 2026/4/8 下午4:09
*/
public String doChatWithTools(String message, String chatId) {
ChatResponse response = chatClient
.prompt()
.user(message)
.advisors(spec -> spec.param(ChatMemory.CONVERSATION_ID, chatId))
.advisors(new JxLoveAppLoggerAdvisor())
.toolCallbacks(allTools)
.call()
.chatResponse();
String content = response.getResult().getOutput().getText();
log.info("content: {}", content);
return content;
}
测试
void doChatWithTools() {
testMessage("周末想带女朋友去上海约会,推荐几个适合情侣的小众打卡地?");
testMessage("最近和对象吵架了,看看小冷的社区里(doomwatcher2004.github.io)的其他情侣是怎么解决矛盾的?");
testMessage("直接下载一张适合做手机壁纸的星空情侣图片为文件");
testMessage("执行 Python3 脚本来生成数据分析报告");
testMessage("保存我的恋爱档案为文件");
testMessage("生成一份‘七夕约会计划’PDF,包含餐厅预订、活动流程和礼物清单");
}
private void testMessage(String message) {
String chatId = UUID.randomUUID().toString();
String answer = loveApp.doChatWithTools(message, chatId);
Assertions.assertNotNull(answer);
}
效果
效果居多 这里展示部分 代码没有问题

工具进阶知识
其实关于工具调用,掌握核心概念和工具开发方法就足够了,但是为了帮大家更好地理解 Spring AI 的工具调用机制(更好地吊打面试官),还是给大家讲一些进阶知识,无需记忆,了解即可。
工具底层数据结构
让我们思考一个问题:AI 怎么知道要如何调用工具?输出结果中应该包含哪些参数来调用工具呢?
Spring AI 工具调用的核心在于 ToolCallback 接口,它是所有工具实现的基础。先分析下该接口的源码:
这个接口中:
getToolDefinition()提供了工具的基本定义,包括名称、描述和调用参数,这些信息会传递给 AI 模型,帮助模型了解什么时候应该调用这个工具、以及如何构造参数getToolMetadata()提供了处理工具的附加信息,比如是否直接返回结果等控制选项- 两个
call()方法是工具的执行入口,分别支持有上下文和无上下文的调用场景
工具定义类 ToolDefinition 的结构如下图,包含名称、描述和调用工具的参数:

但为什么我们刚刚定义工具时,直接通过注解就能把方法变成工具呢?
这是因为,当使用注解定义工具时,Spring AI 会做大量幕后工作:
JsonSchemaGenerator会解析方法签名和注解,自动生成符合 JSON Schema 规范的参数定义,作为 ToolDefinition 的一部分提供给 AI 大模型ToolCallResultConverter负责将各种类型的方法返回值统一转换为字符串,便于传递给 AI 大模型处理MethodToolCallback实现了对注解方法的封装,使其符合ToolCallback接口规范
这种设计使我们可以专注于业务逻辑实现,无需关心底层通信和参数转换的复杂细节。如果需要更精细的控制,我们可以自定义 ToolCallResultConverter 来实现特定的转换逻辑,例如对某些特殊对象的自定义序列化。
工具上下文
在实际应用中,工具执行可能需要额外的上下文信息,比如登录用户信息、会话 ID 或者其他环境参数。Spring AI 通过 ToolContext 提供了这一能力。
String loginUserName = getLoginUserName();
String response = chatClient
.prompt("帮我查询用户信息")
.tools(new CustomerTools())
.toolContext(Map.of("userName", "小冷"))
.call()
.content();
System.out.println(response);
//在工具中使用上下文参数。从数据库中查询 小冷 的信息:
class CustomerTools {
@Tool(description = "Retrieve customer information")
Customer getCustomerInfo(Long id, ToolContext toolContext) {
return customerRepository.findById(id, toolContext.get("userName"));
}
}
立即返回
有时候,工具执行的结果不需要再经过 AI 模型处理,而是希望直接返回给用户(比如生成 PDF 文档)。Spring AI 通过 returnDirect 属性支持这一功能,流程如图:
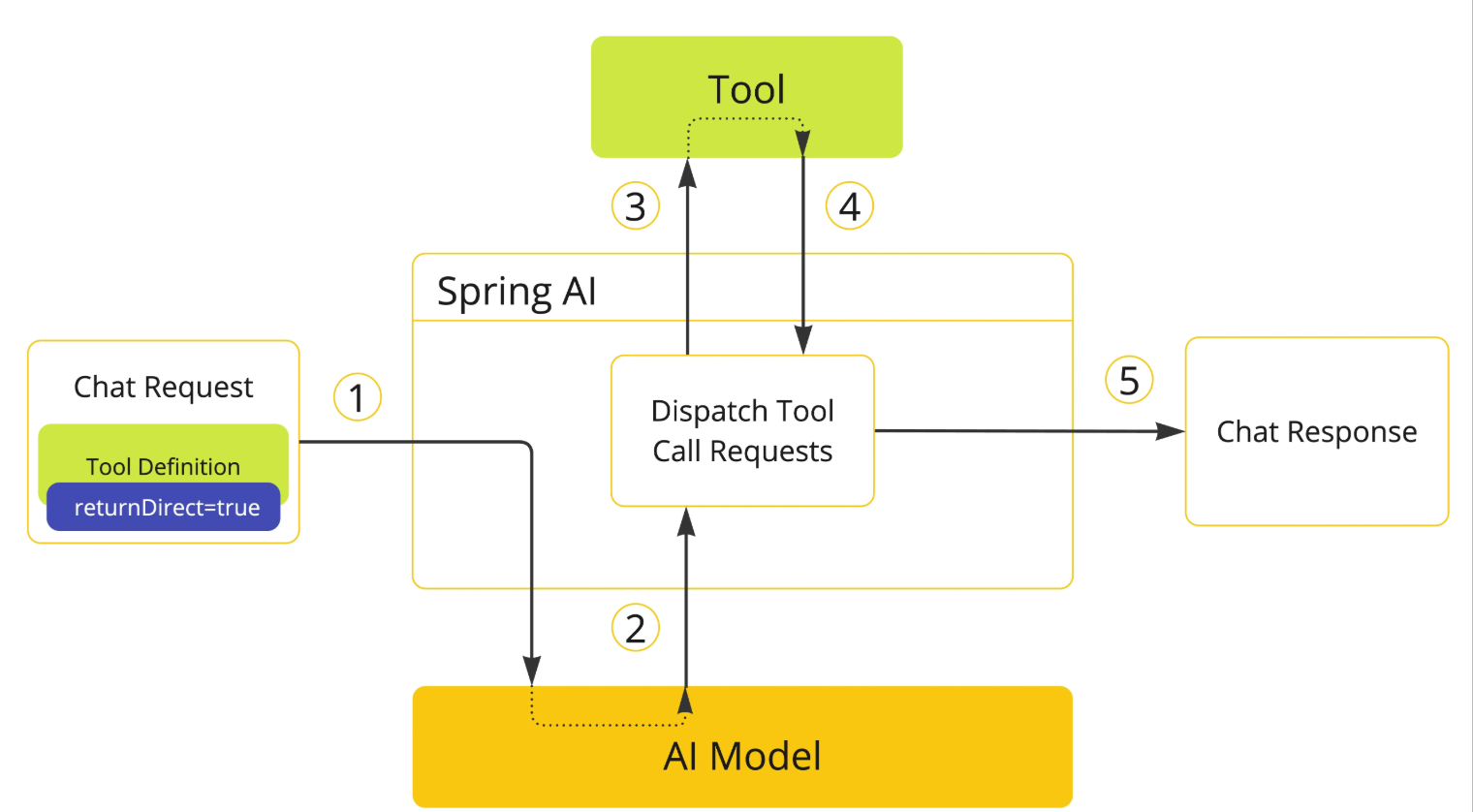
立即返回模式改变了工具调用的基本流程:
- 定义工具时,将
returnDirect属性设为true - 当模型请求调用这个工具时,应用程序执行工具并获取结果
- 结果直接返回给调用者,不再 发送回模型进行进一步处理
这种模式很适合需要返回二进制数据(比如图片 / 文件)的工具、返回大量数据而不需要 AI 解释的工具,以及产生明确结果的操作(如数据库操作)。
启用立即返回的方法非常简单,使用注解方式时指定 returnDirect 参数:
class CustomerTools {
@Tool(description = "Retrieve customer information", returnDirect = true)
Customer getCustomerInfo(Long id) {
return customerRepository.findById(id);
}
}
工具底层执行原理
ToolCallingManager
ToolCallingManager 接口可以说是 Spring AI 工具调用中最值得学习的类了。它是 管理 AI 工具调用全过程 的核心组件,负责根据 AI 模型的响应执行对应的工具并返回执行结果给大模型。此外,它还支持异常处理,可以统一处理工具执行过程中的错误情况。
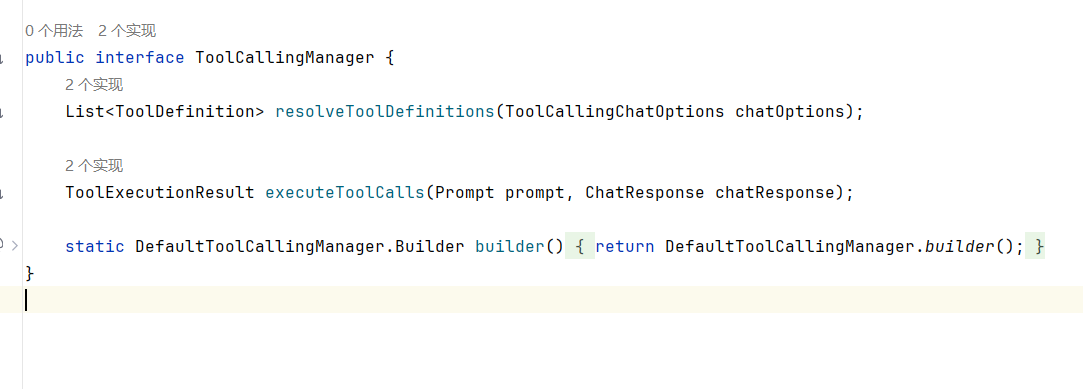
其中的 2 个核心方法:
- resolveToolDefinitions:从模型的工具调用选项中解析工具定义
- executeToolCalls:执行模型请求对应的工具调用
支持自定义manager
@Bean
ToolCallingManager toolCallingManager() {
return ToolCallingManager.builder().build();
}
默认实现的
executeToolCalls
public ToolExecutionResult executeToolCalls(Prompt prompt, ChatResponse chatResponse) {
Assert.notNull(prompt, "prompt cannot be null");
Assert.notNull(chatResponse, "chatResponse cannot be null");
Optional<Generation> toolCallGeneration = chatResponse.getResults().stream().filter((g) -> {
return !CollectionUtils.isEmpty(g.getOutput().getToolCalls());
}).findFirst();
if (toolCallGeneration.isEmpty()) {
throw new IllegalStateException("No tool call requested by the chat model");
} else {
AssistantMessage assistantMessage = ((Generation)toolCallGeneration.get()).getOutput();
ToolContext toolContext = buildToolContext(prompt, assistantMessage);
//进入到调用工具方法
InternalToolExecutionResult internalToolExecutionResult = this.executeToolCall(prompt, assistantMessage, toolContext);
List<Message> conversationHistory = this.buildConversationHistoryAfterToolExecution(prompt.getInstructions(), assistantMessage, internalToolExecutionResult.toolResponseMessage());
return ToolExecutionResult.builder().conversationHistory(conversationHistory).returnDirect(internalToolExecutionResult.returnDirect()).build();
}
}
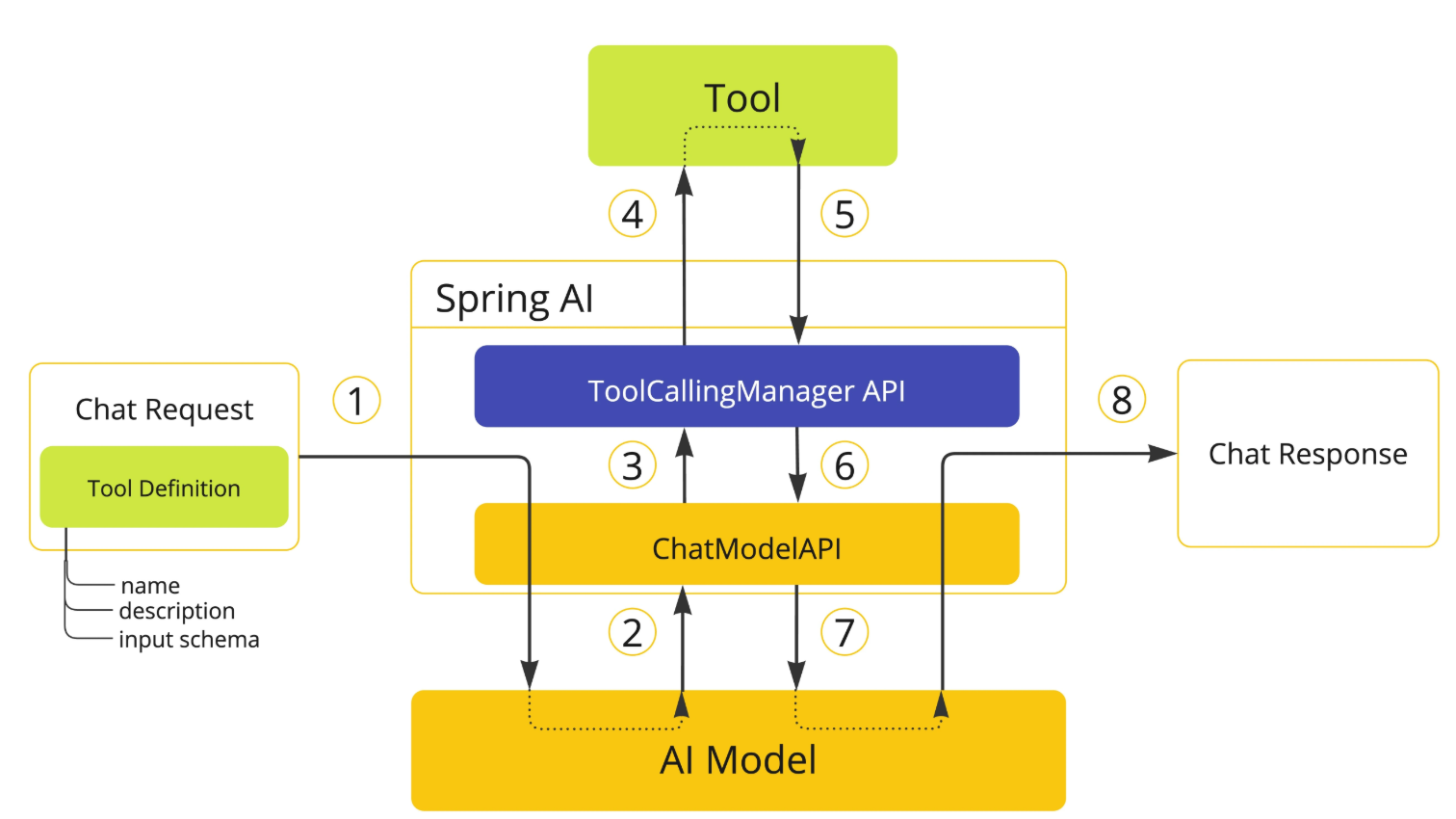
框架控制的工具执行
这是默认且最简单的模式,由 Spring AI 框架自动管理整个工具调用流程。所以我们刚刚开发时,基本没写几行非业务逻辑的代码,大多数活儿都交给框架负重前行了。
在这种模式下:
- 框架自动检测模型是否请求调用工具
- 自动执行工具调用并获取结果
- 自动将结果发送回模型
- 管理整个对话流程直到得到最终答案
调用原理
private InternalToolExecutionResult executeToolCall(Prompt prompt, AssistantMessage assistantMessage, ToolContext toolContext) {
List<ToolCallback> toolCallbacks = List.of();
ChatOptions var6 = prompt.getOptions();
if (var6 instanceof ToolCallingChatOptions toolCallingChatOptions) {
toolCallbacks = toolCallingChatOptions.getToolCallbacks();
}
List<ToolResponseMessage.ToolResponse> toolResponses = new ArrayList();
Boolean returnDirect = null;
Iterator var7 = assistantMessage.getToolCalls().iterator();
while(var7.hasNext()) {
AssistantMessage.ToolCall toolCall = (AssistantMessage.ToolCall)var7.next();
logger.debug("Executing tool call: {}", toolCall.name());
String toolName = toolCall.name();
String toolInputArguments = toolCall.arguments();
String finalToolInputArguments;
if (!StringUtils.hasText(toolInputArguments)) {
logger.warn("Tool call arguments are null or empty for tool: {}. Using empty JSON object as default.", toolName);
finalToolInputArguments = "{}";
} else {
finalToolInputArguments = toolInputArguments;
}
ToolCallback toolCallback = (ToolCallback)toolCallbacks.stream().filter((tool) -> {
return toolName.equals(tool.getToolDefinition().name());
}).findFirst().orElseGet(() -> {
return this.toolCallbackResolver.resolve(toolName);
});
if (toolCallback == null) {
logger.warn("LLM may have adapted the tool name '{}', especially if the name was truncated due to length limits. If this is the case, you can customize the prefixing and processing logic using McpToolNamePrefixGenerator", toolName);
throw new IllegalStateException("No ToolCallback found for tool name: " + toolName);
}
if (returnDirect == null) {
returnDirect = toolCallback.getToolMetadata().returnDirect();
} else {
returnDirect = returnDirect && toolCallback.getToolMetadata().returnDirect();
}
ToolCallingObservationContext observationContext = ToolCallingObservationContext.builder().toolDefinition(toolCallback.getToolDefinition()).toolMetadata(toolCallback.getToolMetadata()).toolCallArguments(finalToolInputArguments).build();
String toolCallResult = (String)ToolCallingObservationDocumentation.TOOL_CALL.observation(this.observationConvention, DEFAULT_OBSERVATION_CONVENTION, () -> {
return observationContext;
}, this.observationRegistry).observe(() -> {
String toolResult;
try {
toolResult = toolCallback.call(finalToolInputArguments, toolContext);
} catch (ToolExecutionException var7) {
ToolExecutionException ex = var7;
toolResult = this.toolExecutionExceptionProcessor.process(ex);
}
observationContext.setToolCallResult(toolResult);
return toolResult;
});
toolResponses.add(new ToolResponseMessage.ToolResponse(toolCall.id(), toolName, toolCallResult != null ? toolCallResult : ""));
}
return new InternalToolExecutionResult(ToolResponseMessage.builder().responses(toolResponses).build(), returnDirect);
}
调用流程图
用户控制的工具执行
对于需要更精细控制的复杂场景,Spring AI 提供了用户控制模式,可以通过设置 ToolCallingChatOptions 的 internalToolExecutionEnabled 属性为 false 来禁用内部工具执行。
ChatOptions chatOptions = ToolCallingChatOptions.builder()
.toolCallbacks(ToolCallbacks.from(new WeatherTools()))
.internalToolExecutionEnabled(false)
.build();
然后我们就可以自己从 AI 的响应结果中提取工具调用列表,再依次执行了:
ToolCallingManager toolCallingManager = DefaultToolCallingManager.builder().build();
Prompt prompt = new Prompt("小冷新写的AI学习笔记", chatOptions);
ChatResponse chatResponse = chatModel.call(prompt);
while (chatResponse.hasToolCalls()) {
ToolExecutionResult toolExecutionResult = toolCallingManager.executeToolCalls(prompt, chatResponse);
prompt = new Prompt(toolExecutionResult.conversationHistory(), chatOptions);
chatResponse = chatModel.call(prompt);
}
System.out.println(chatResponse.getResult().getOutput().getText());
这样一来,我们就可以:
- 在工具执行前后插入自定义逻辑
- 实现更复杂的工具调用链和条件逻辑
- 和其他系统集成,比如追踪 AI 调用进度、记录日志等
- 实现更精细的错误处理和重试机制
官方还提供了一个更复杂的代码示例,结合用户控制的工具执行 + 会话记忆特性,感兴趣的同学 参考文档 了解即可。
异常处理
工具执行过程中可能会发生各种异常,Spring AI 提供了灵活的异常处理机制,通过 ToolExecutionExceptionProcessor 接口实现。
@FunctionalInterface
public interface ToolExecutionExceptionProcessor {
String process(ToolExecutionException exception);
}
默认实现类 DefaultToolExecutionExceptionProcessor 提供了两种处理策略:
- alwaysThrow 参数为 false:将异常信息作为错误消息返回给 AI 模型,允许模型根据错误信息调整策略
- alwaysThrow 参数为 true:直接抛出异常,中断当前对话流程,由应用程序处理
可以根据需要定制处理策略,声明一个 ToolExecutionExceptionProcessor Bean 即可:
@Bean
ToolExecutionExceptionProcessor toolExecutionExceptionProcessor() {
return new DefaultToolExecutionExceptionProcessor(true);
}
我们还可以自定义异常处理器来实现更复杂的策略,比如根据异常类型决定是返回错误消息还是抛出异常,或者实现重试逻辑:
@Bean
ToolExecutionExceptionProcessor customExceptionProcessor() {
return exception -> {
if (exception.getCause() instanceof IOException) {
return "Unable to access external resource. Please try a different approach.";
} else if (exception.getCause() instanceof SecurityException) {
throw exception;
}
return "Error executing tool: " + exception.getMessage();
};
}
工具解析
前面提到,除了直接提供 ToolCallback 实例外,Spring AI 还支持通过名称动态解析工具,这是通过ToolCallbackResolver 接口实现的。代码如下,作用就是将名称解析为 ToolCallback 工具对象:
public interface ToolCallbackResolver {
@Nullable
ToolCallback resolve(String toolName);
}
Spring AI 默认使用 DelegatingToolCallbackResolver,它将工具解析任务委托给一系列解析器:
SpringBeanToolCallbackResolver:从 Spring 容器中查找工具,支持函数式接口 BeanStaticToolCallbackResolver:从预先注册的 ToolCallback 工具列表中查找。当使用 Spring Boot 自动配置时,该解析器会自动配置应用上下文中定义的所有ToolCallback类型的 Bean。
MCP
MCP(Model Context Protocol,模型上下文协议)是一种开放标准,目的是增强 AI 与外部系统的交互能力。MCP 为 AI 提供了与外部工具、资源和服务交互的标准化方式,让 AI 能够访问最新数据、执行复杂操作,并与现有系统集成。
根据 官方定义,MCP 是一种开放协议,它标准化了应用程序如何向大模型提供上下文的方式。可以将 MCP 想象成 AI 应用的 USB 接口。就像 USB 为设备连接各种外设和配件提供了标准化方式一样,MCP 为 AI 模型连接不同的数据源和工具提供了标准化的方法。
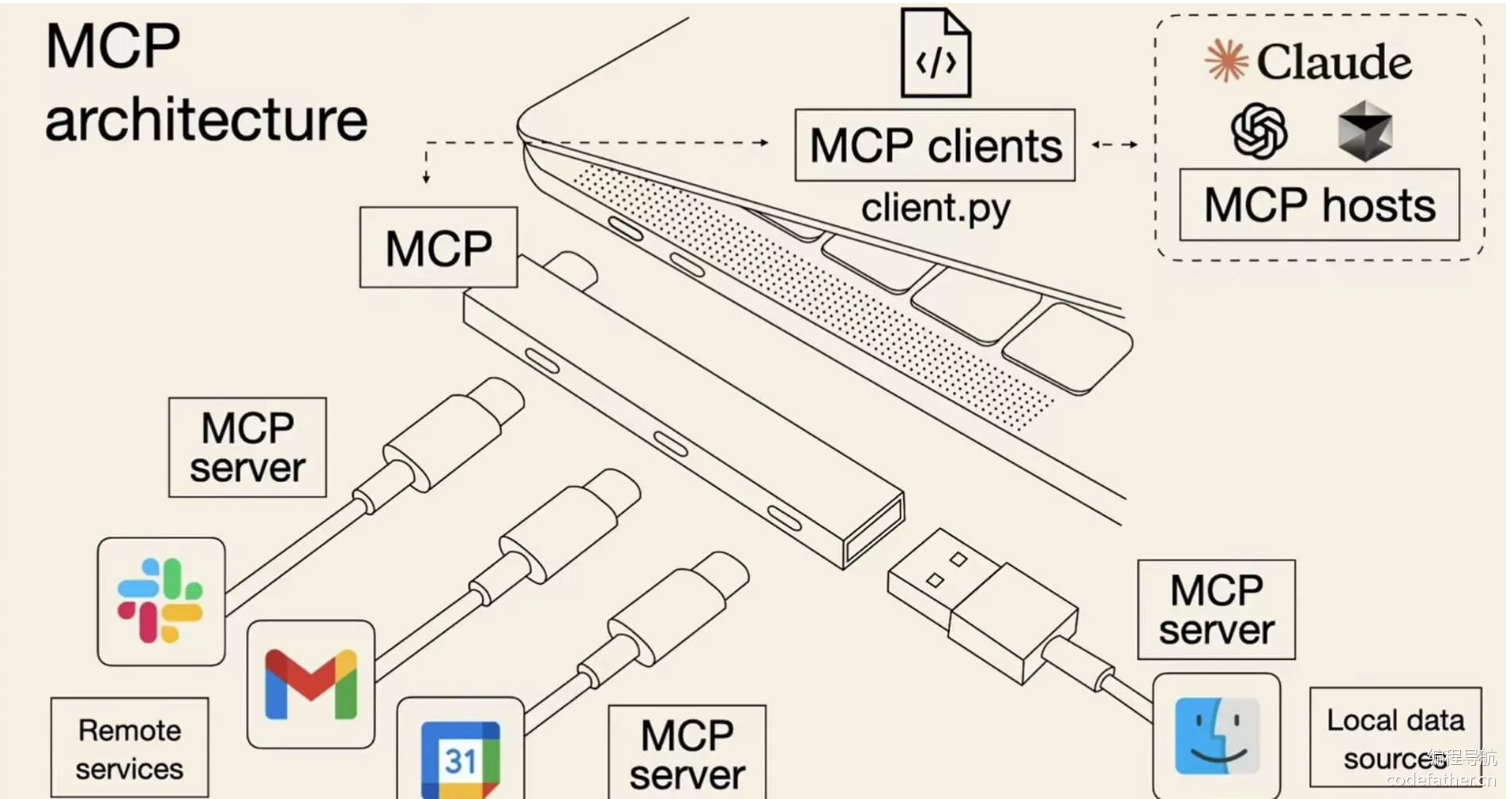
你可以理解成一个标准化中转站协议 可以动态的去获取到别人编写好的api 来调用
这就是 MCP 的三大作用:
- 轻松增强 AI 的能力
- 统一标准,降低使用和理解成本
- 打造服务生态,造福广大开发者
MCP 的核心是 “客户端 - 服务器” 架构,其中 MCP 客户端主机可以连接到多个服务器。客户端主机是指希望访问 MCP 服务的程序,比如 Claude Desktop、IDE、AI 工具或部署在服务器上的项目。
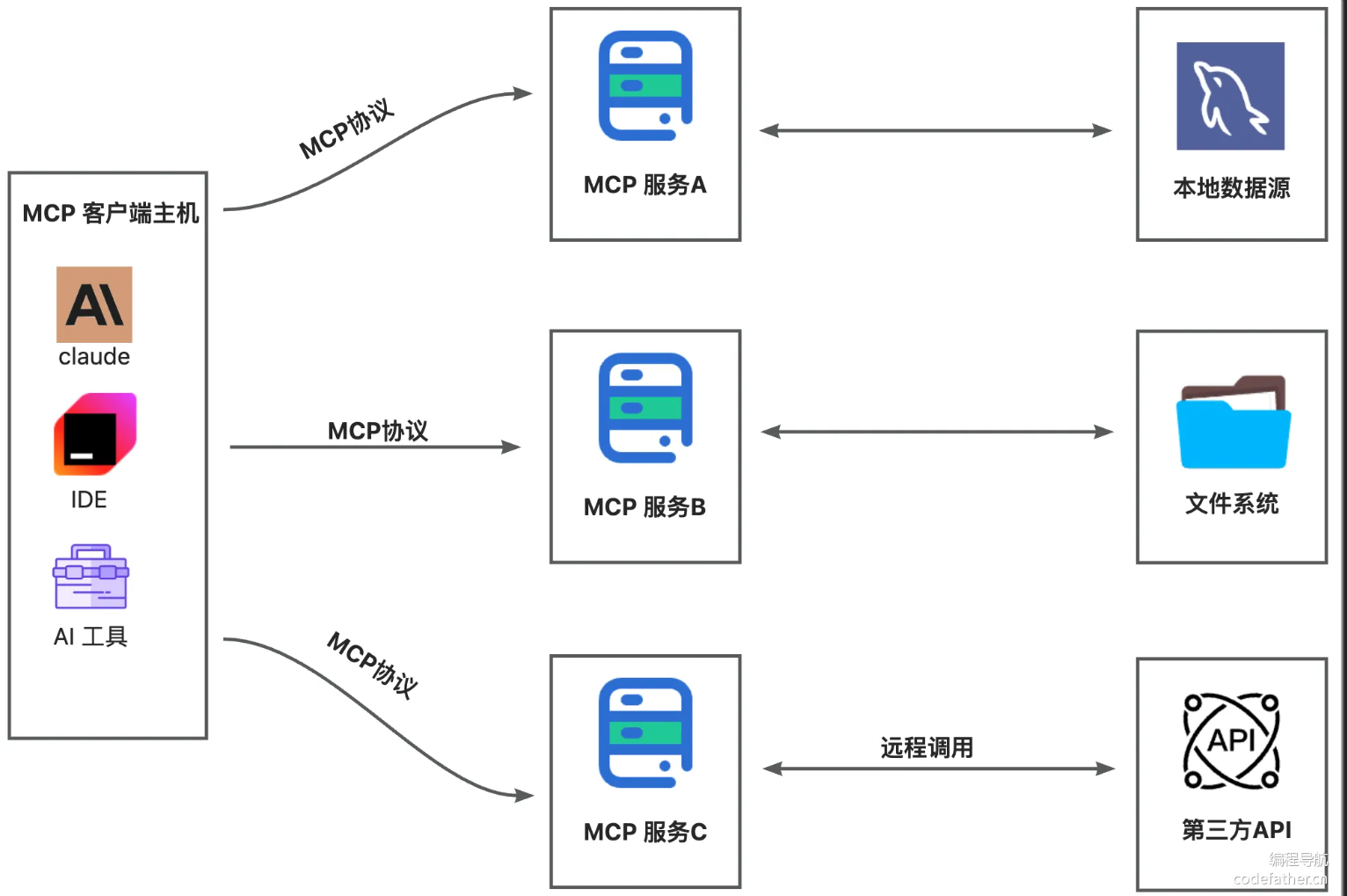
我们在上一个知识点 学习了 工具调用 但是我们现在可以通过 MCP 协议可以直接使用别人写好的 api 这样我们就不需要编写工具的内容了 直接可以使用线程的轮子 不只是逻辑方法 工具 还包括一些资源
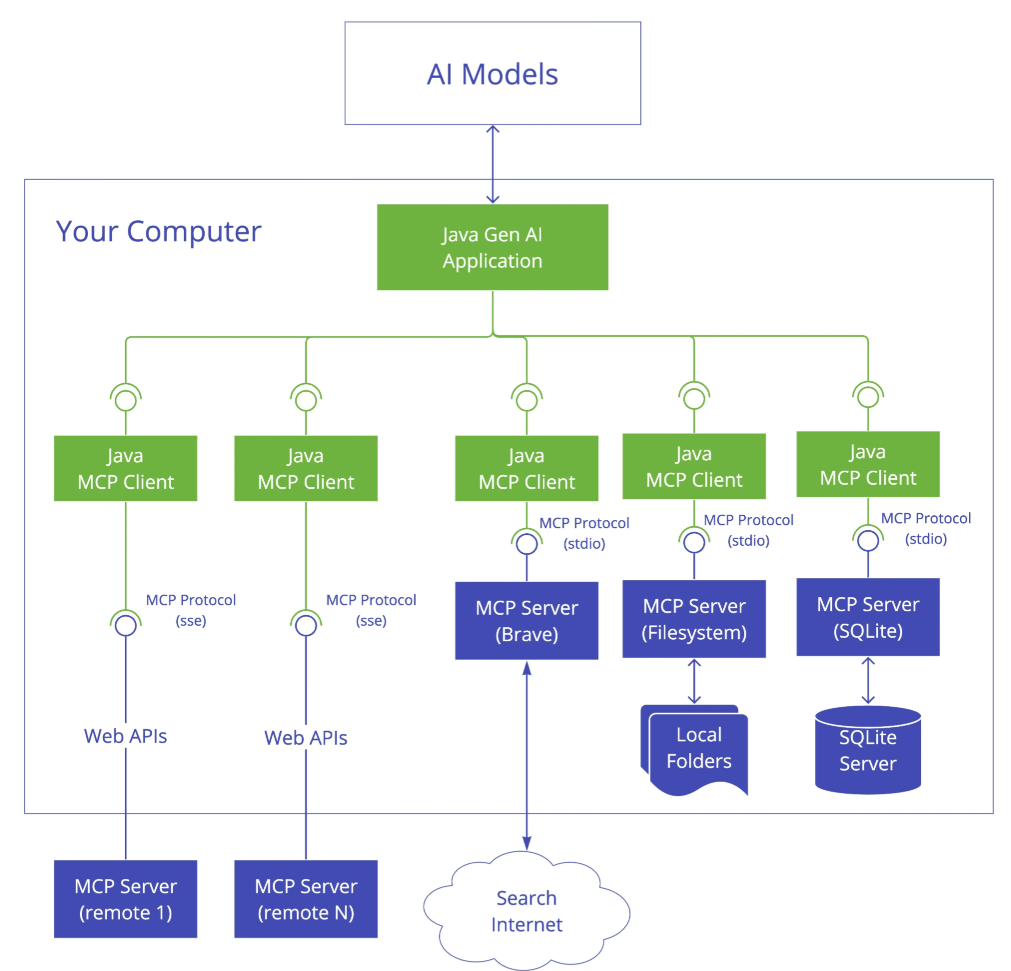
SDK 3 层架构
如果我们要在程序中使用 MCP 或开发 MCP 服务,可以引入 MCP 官方的 SDK,比如 Java SDK。让我们先通过 MCP 官方文档了解 MCP SDK 的架构,主要分为 3 层:
- 客户端 / 服务器层:McpClient 处理客户端操作,而 McpServer 管理服务器端协议操作。两者都使用 McpSession 进行通信管理。
- 会话层(McpSession):通过 DefaultMcpSession 实现管理通信模式和状态。
- 传输层(McpTransport):处理 JSON-RPC 消息序列化和反序列化,支持多种传输实现,比如 Stdio 标准 IO 流传输和 HTTP SSE 远程传输。
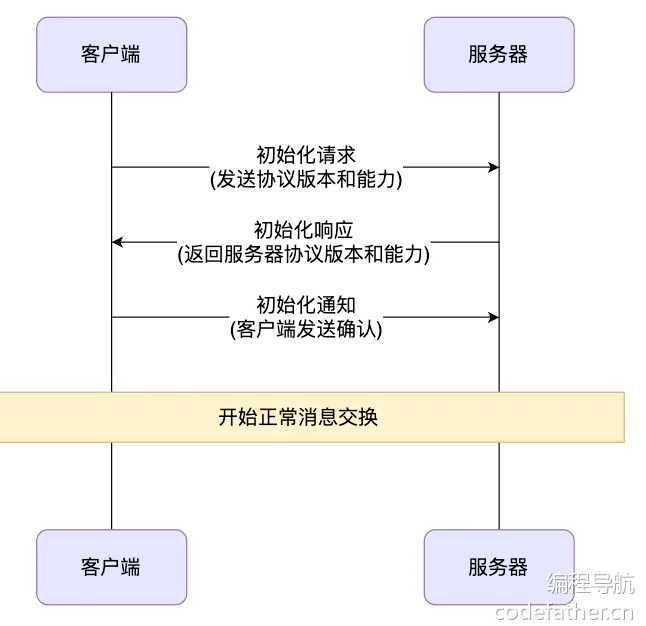
MCP 客户端
MCP Client 是 MCP 架构中的关键组件,主要负责和 MCP 服务器建立连接并进行通信。它能自动匹配服务器的协议版本、确认可用功能、负责数据传输和 JSON-RPC 交互。此外,它还能发现和使用各种工具、管理资源、和提示词系统进行交互。
除了这些核心功能,MCP 客户端还支持一些额外特性,比如根管理、采样控制,以及同步或异步操作。为了适应不同场景,它提供了多种数据传输方式,包括:
- Stdio 标准输入 / 输出:适用于本地调用
- 基于 Java HttpClient 和 WebFlux 的 SSE 传输:适用于远程调用
客户端可以通过不同传输方式调用不同的 MCP 服务,可以是本地的、也可以是远程的。如图:
MCP 核心概念
按照官方的说法,总共有 6 大核心概念。除了 Tools 工具之外的其他概念都不是很实用,如果要进一步学习可以阅读对应的官方文档。
- Resources 资源:让服务端向客户端提供各种数据,比如文本、文件、数据库记录、API 响应等,客户端可以决定什么时候使用这些资源。使 AI 能够访问最新信息和外部知识,为模型提供更丰富的上下文。
- Prompts 提示词:服务端可以定义可复用的提示词模板和工作流,供客户端和用户直接使用。它的作用是标准化常见的 AI 交互模式,比如能作为 UI 元素(如斜杠命令、快捷操作)呈现给用户,从而简化用户与 LLM 的交互过程。
- Tools 工具:MCP 中最实用的特性,服务端可以提供给客户端可调用的函数,使 AI 模型能够执行计算、查询信息或者和外部系统交互,极大扩展了 AI 的能力范围。
- Sampling 采样:允许服务端通过客户端向大模型发送生成内容的请求(反向请求)。使 MCP 服务能够实现复杂的智能代理行为,同时保持用户对整个过程的控制和数据隐私保护。
- Roots 根目录:MCP 协议的安全机制,定义了服务器可以访问的文件系统位置,限制访问范围,为 MCP 服务提供安全边界,防止恶意文件访问。
- Transports 传输:定义客户端和服务器间的通信方式,包括 Stdio(本地进程间通信)和 SSE(网络实时通信),确保不同环境下的可靠信息交换。
如果要开发 MCP 服务,我们主要关注前 3 个概念,当然,Tools 工具是重中之重!
使用 MCP
本节我们将实战 3 种使用 MCP 的方式:
- 云平台使用 MCP
- 软件客户端使用 MCP
- 程序中使用 MCP
无论是哪种使用方式,原理都是类似的,而且有 2 种可选的使用模式:本地下载 MCP 服务端代码并运行(类似引入了一个 SDK),或者 直接使用已部署的 MCP 服务(类似调用了别人的 API)。
MCP 服务大全
目前已经有很多 MCP 服务市场,开发者可以在这些平台上找到各种现成的 MCP 服务:
- MCP.so:较为主流,提供丰富的 MCP 服务目录
- GitHub Awesome MCP Servers:开源 MCP 服务集合
- 阿里云百炼 MCP 服务市场
- Spring AI Alibaba 的 MCP 服务市场
其中,绝大多数 MCP 服务市场仅提供本地下载 MCP 服务端代码并运行的使用方式,毕竟部署 MCP 服务也是需要成本的。
这里我们使用 高德地图的mcp (请自行去高德开发者平台获取自己的 api key 用于后续的学习)
创建 key

云服务商也提供了打包好的 mcp
比如阿里云百炼平台提供的
ps: mcp 并不稳定 可能会存在根据大模型的理解 多次的调用 会增加很多成本
程序中使用 MCP
让我们利用 Spring AI 框架,在程序中使用 MCP 并完成我们的需求,实现一个能够根据另一半的位置推荐约会地点的 AI 助手。
💡 类似的 Java MCP 开发框架还有 Solon AI MCP,但由于我们更多地使用 Spring 生态,所以还是推荐使用 Spring AI 框架。
首先了解 Spring AI MCP 客户端的基本使用方法。建议参考 Spring AI Alibaba 的文档,因为 Spring AI 官方文档 更新的太快了,包的路径可能会变动。
1)在 Maven 中央仓库 中可以找到正确的依赖,引入到项目中:
<!-- Source: https://mvnrepository.com/artifact/org.springframework.ai/spring-ai-starter-mcp-client -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-client</artifactId>
<version>1.1.3</version>
<scope>compile</scope>
</dependency>
配置你的 MCP json
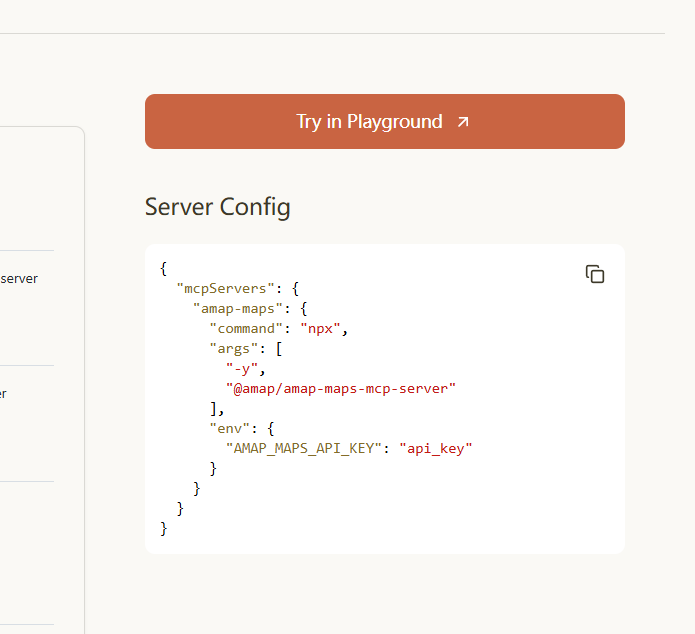
这里因为我们是 windows 系统 根据官方文档的模版 使用如下配置
{
"mcpServers": {
"amap-maps": {
"command": "cmd.exe",
"args": [
"/c",
"npx",
"-y",
"@amap/amap-maps-mcp-server"
],
"env": {
"AMAP_MAPS_API_KEY": "you apikey"
}
}
}
}
在 yml 新增配置 指定mcp服务文件的地址
mcp:
client:
stdio:
servers-configuration: classpath:mcp-servers.json
在
loveapp新增方法
//使用toolCallbackProvider整合 mcp工具
@Resource
private ToolCallbackProvider toolCallbackProvider;
/**
* 调用高德的MCP服务
* toolCallbackProvider spring 会把MCP文件中的工具全部整合到 provider中 供我们使用
*
* @author 冷环渊
* date: 2026/4/8 下午4:09
*/
public String doChatWithMCP(String message, String chatId) {
ChatResponse response = chatClient
.prompt()
.user(message)
.advisors(spec -> spec.param(ChatMemory.CONVERSATION_ID, chatId))
.advisors(new JxLoveAppLoggerAdvisor())
.toolCallbacks(toolCallbackProvider)
.call()
.chatResponse();
String content = response.getResult().getOutput().getText();
log.info("content: {}", content);
return content;
}
到这里就完成了 是不是非常的开箱即用, spring ai一贯的封装风格 非常的到位将配置服务开发到极致
测试用例
@Test
void doChatWithMCP() {
String chatId = UUID.randomUUID().toString();
String message = "我和我的女朋友居住在深圳南山区 , 请帮我找到南山区五公里内最适合的约会地点";
String answer = loveApp.doChatWithTools(message, chatId);
Assertions.assertNotNull(answer);
}
测试结果
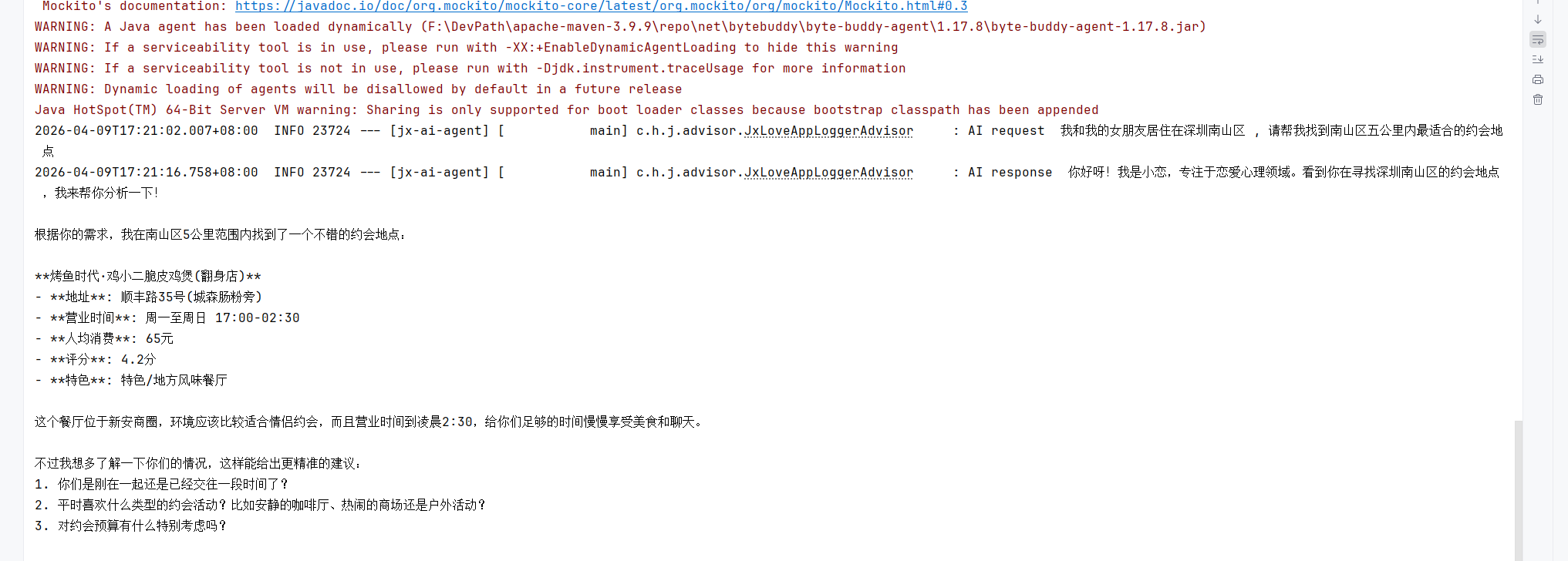
高德平台查看调用该情况 是否使用了 mcp提供的工具
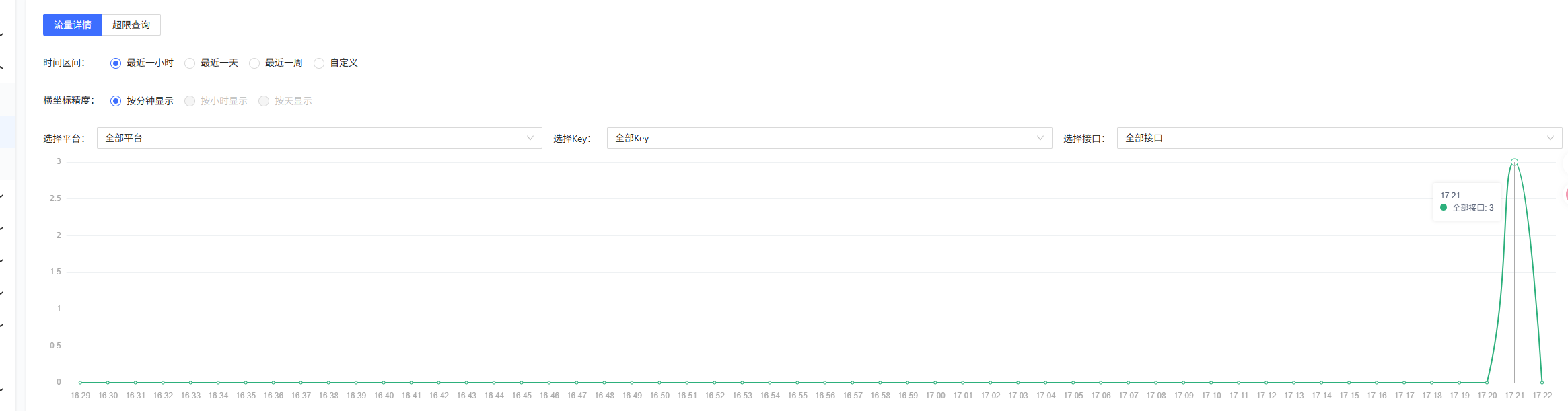
从这段代码我们能够看出,MCP 调用的本质就是类似工具调用,并不是让 AI 服务器主动去调用 MCP 服务,而是告诉 AI “MCP 服务提供了哪些工具”,如果 AI 想要使用这些工具完成任务,就会告诉我们的后端程序,后端程序在执行工具后将结果返回给 AI,最后由 AI 总结并回复。流程图如下:
Spring AI MCP 开发模式
客户端开发主要基于 Spring AI MCP Client Boot Starter,能够自动完成客户端的初始化、管理多个客户端实例、自动清理资源等。
引入依赖
Spring AI 提供了 2 种客户端 SDK,分别支持非响应式和响应式编程,可以根据需要选择对应的依赖包:
spring-ai-starter-mcp-client:核心启动器,提供 STDIO 和基于 HTTP 的 SSE 支持spring-ai-starter-mcp-client-webflux:基于 WebFlux 响应式的 SSE 传输实现
配置连接
引入依赖后,需要配置与服务器的连接,Spring AI 支持两种配置方式:
-
直接写入配置文件,这种方式同时支持 stdio 和 SSE 连接方式。
-
引用 Claude Desktop 格式 的 JSON 文件,目前仅支持 stdio 连接方式。(我们刚才在测试中使用的方式)
使用服务
启动项目时,Spring AI 会自动注入一些 MCP 相关的 Bean。
如果你想完全自主控制 MCP 客户端的行为,可以使用 McpClient Bean,支持同步和异步:
@Autowired
private List<McpSyncClient> mcpSyncClients;
@Autowired
private List<McpAsyncClient> mcpAsyncClients;
开发者还可以通过编写自定义 Client Bean 来 定制客户端行为,比如设置请求超时时间、设置文件系统根目录的访问范围、自定义事件处理器、添加特定的日志处理逻辑。
MCP 工具类
Spring AI 还提供了一系列 辅助 MCP 开发的工具类,用于 MCP 和 ToolCallback 之间的互相转换。
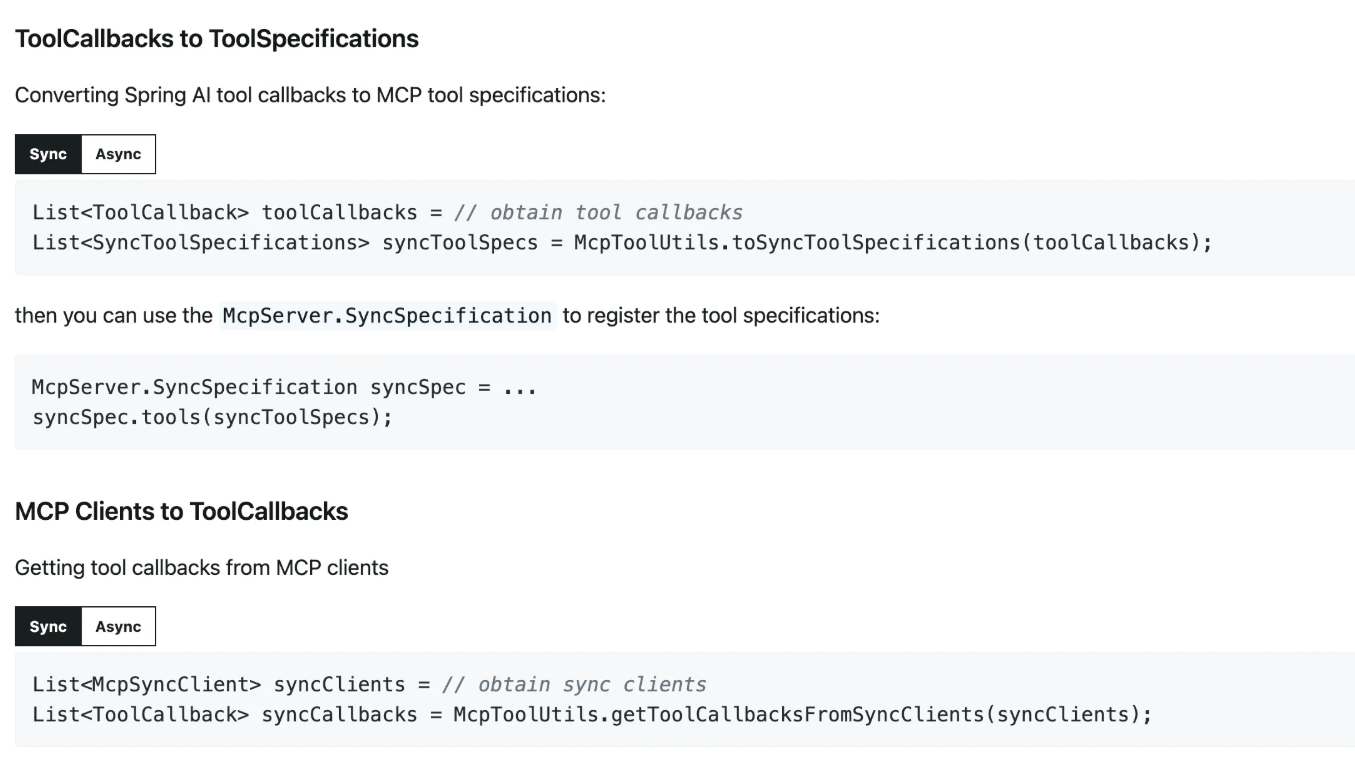
MCP开发实战 图片搜索服务
注册图片搜索服务
我们可以使用 免费的网站来直接构建图片搜索服务 https://www.pexels.com/api/
创建一个项目
然后就可以获取到你的 api key 之后用于服务的使用了
创建服务模块
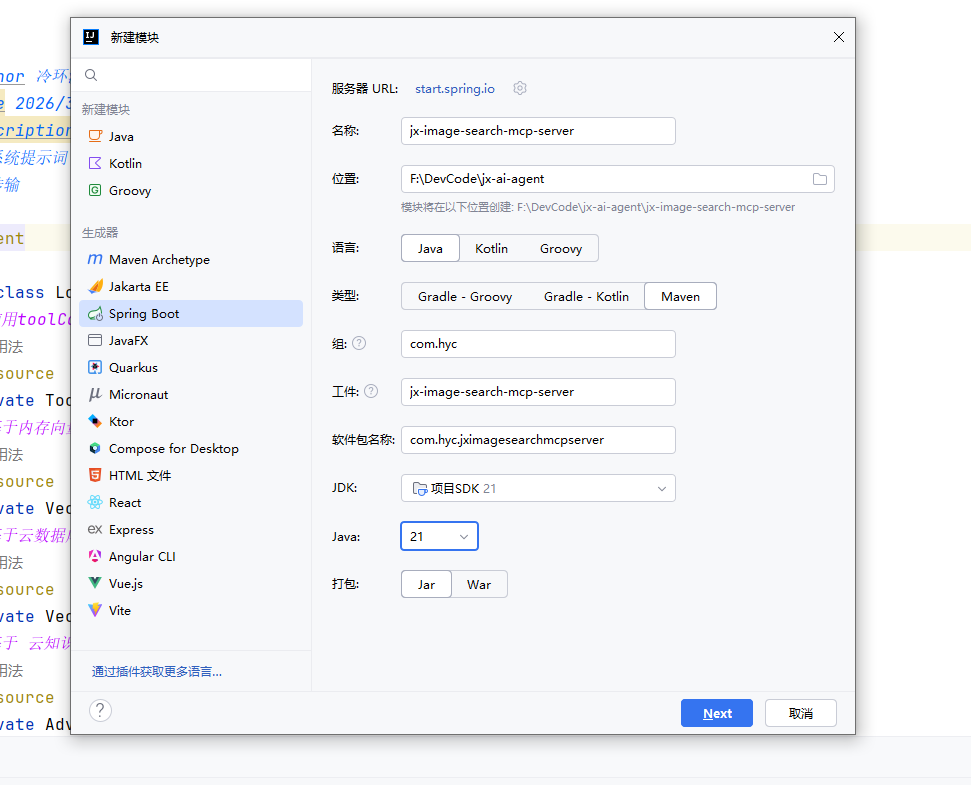
依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<!--mcp spring ai 服务端依赖-->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-server-webmvc</artifactId>
<version>1.1.3</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.37</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
因为官方文档中mcp 有两种传输方式 这里我们编写两种配置文件用于 不同的传输方式
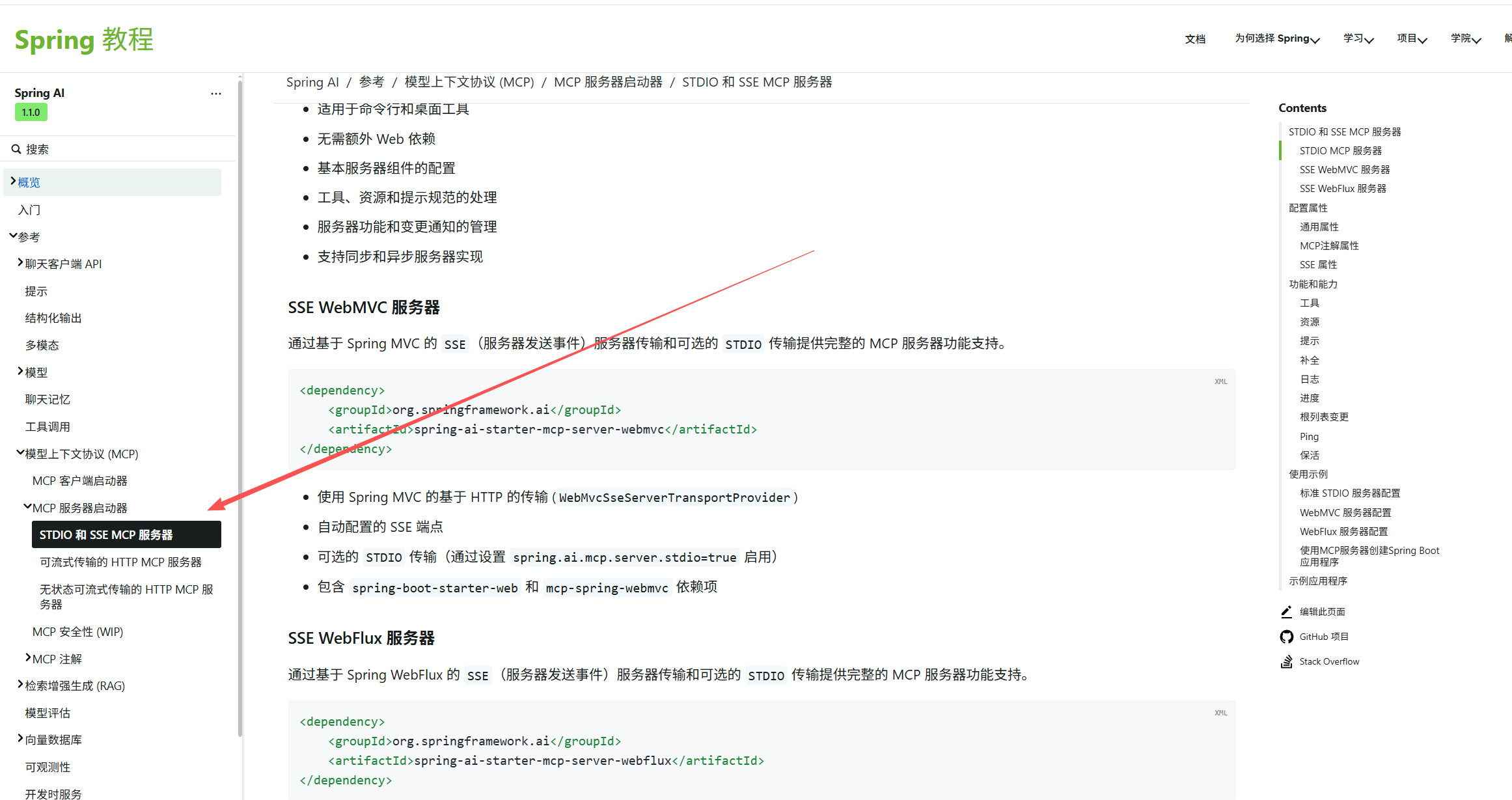
application-sse
spring:
ai:
mcp:
server:
name: jx-image-search-mcp-server
version: 0.0.1
type: sync
stdio: false
application-stdio
spring:
ai:
mcp:
server:
name: jx-image-search-mcp-server
version: 0.0.1
type: sync
stdio: true
# 这里我们用本地项目 这里我们不需要去使用web容器 把web程序关掉
main:
web-application-type: none
banner-mode: off
区别其实就是一些 web配置 和 stdio的参数 , 这里我们为了方便切换 所以选择分成两个配置文件
入口配置文件
spring:
application:
name: jx-image-search-mcp-server
profiles:
active: stdio
server:
port: 8001
搜索工具代码
package com.hyc.jximagesearchmcpserver.tools;
import cn.hutool.core.util.StrUtil;
import cn.hutool.http.HttpUtil;
import cn.hutool.json.JSONObject;
import cn.hutool.json.JSONUtil;
import org.springframework.ai.tool.annotation.Tool;
import org.springframework.ai.tool.annotation.ToolParam;
import org.springframework.stereotype.Service;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
/**
* @author 冷环渊
* @date 2026/4/11 下午10:00
* @description ImageSearchTool
*/
@Service
public class ImageSearchTool {
private static final String API_KEY = "you api key";
private static final String API_URL = "https://api.pexels.com/v1/search";
@Tool(description = "search image from web")
public String searchImage(@ToolParam(description = "Search query keyword") String query) {
try {
return String.join(",", searchMediumImages(query));
} catch (Exception e) {
return "Error search image: " + e.getMessage();
}
}
public List<String> searchMediumImages(String query) {
Map<String, String> headers = new HashMap<>();
headers.put("Authorization", API_KEY);
Map<String, Object> params = new HashMap<>();
params.put("query", query);
String response = HttpUtil.createGet(API_URL)
.addHeaders(headers)
.form(params)
.execute()
.body();
return JSONUtil.parseObj(response)
.getJSONArray("photos")
.stream()
.map(photoObj -> (JSONObject) photoObj)
.map(photoObj -> photoObj.getJSONObject("src"))
.map(photo -> photo.getStr("medium"))
.filter(StrUtil::isNotBlank)
.collect(Collectors.toList());
}
}
测试类
@SpringBootTest
class ImageSearchToolTest {
@Resource
private ImageSearchTool imageSearchTool;
@Test
void searchImage() {
String result = imageSearchTool.searchImage("pretty woman");
Assertions.assertNotNull(result);
}
}
测试结果
将工具注册到spring中
然后使用 mvn packge 命令打包 方便之后使用
@SpringBootApplication
public class JxImageSearchMcpServerApplication {
public static void main(String[] args) {
SpringApplication.run(JxImageSearchMcpServerApplication.class, args);
}
/**
* 将图片搜索工具注册到 spring中
* 生成一个方法提供器
*
* @author 冷环渊
* date: 2026/4/11 下午10:08
*/
@Bean
public ToolCallbackProvider imageSearchToolCallbackProvider(ImageSearchTool imageSearchTool) {
return MethodToolCallbackProvider.builder()
.toolObjects(imageSearchTool)
.build();
}
}
使用服务
在jx-agent 的mcpserver配置中 添加我们刚才写好的信息
"jx-image-search-mcp-server": {
"command": "java",
"args": [
"-Dspring.ai.mcp.server.stdio=true",
"-Dspring.main.web-application-type=none",
"-Dlogging.pattern.console=",
"-jar",
"jx-image-search-mcp-server/target/jx-image-search-mcp-server-0.0.1-SNAPSHOT.jar"
],
"env": {}
}
就可以直接使用我们的工具了
直接开始测试
@Test
void doChatWithMCP() {
String chatId = UUID.randomUUID().toString();
String message = "帮我生成一些 能够哄女朋友开心的图片";
String answer = loveApp.doChatWithMCP(message, chatId);
Assertions.assertNotNull(answer);
}

我们只用本地的你就会发现和 这种方式和我们直接编写 工具没什么区别 但是他的另一个好处是 工程师们 可以直接将自己的工具发布让其他人可以快乐的接入 那么这就变得很有价值了
切换 SSE
切换配置到 sse
以debug的模式启动主类 , 去修改 jx-agent的配置
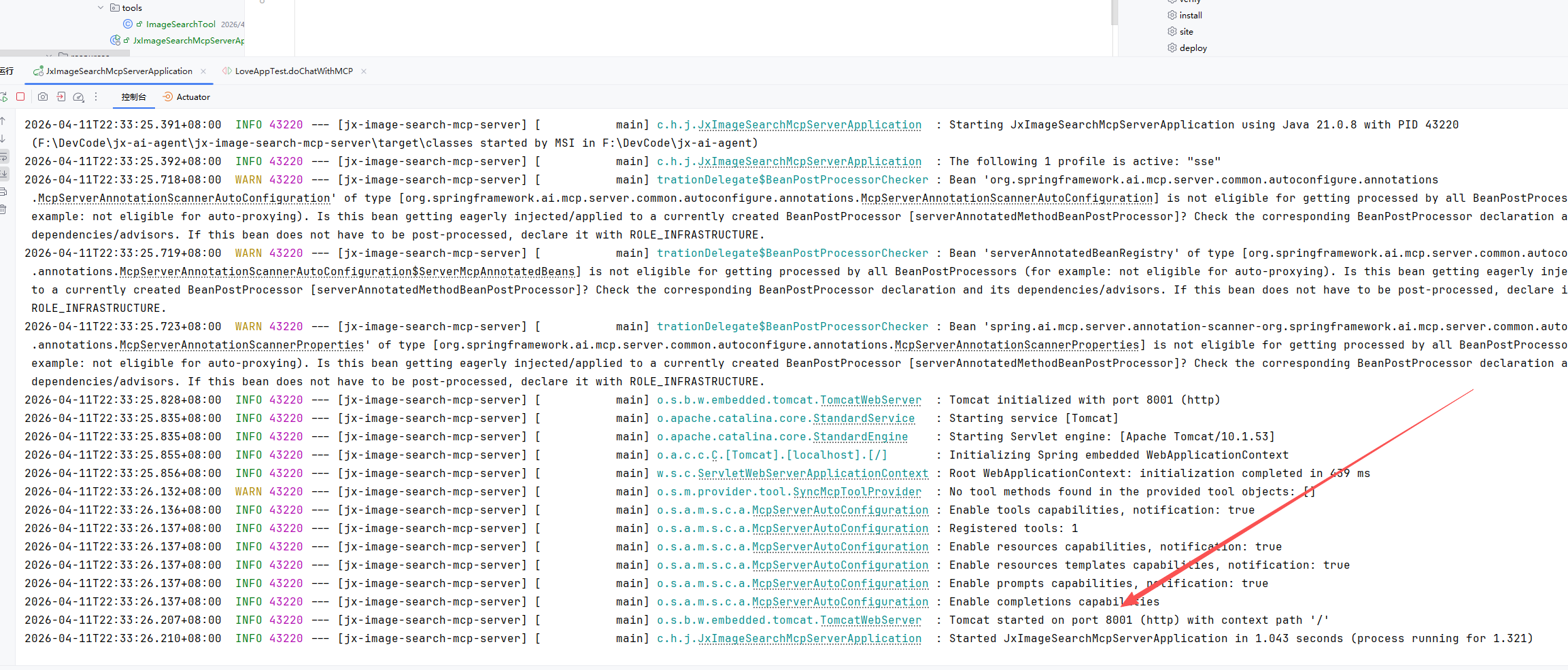
sse配置
mcp:
client:
sse:
connections:
server1:
url: http://localhost:8001
测试
启动 image -mcp -server 然后启动我们的主程序


可以看到 我们在使用 sse的时候 mcpserver会出现访问日志 这就说明我们成功调通了
最佳实践
注意事项
已经学会如何开发 MCP 服务端和客户端后,我们来学习一些 MCP 开发的最佳实践。
1)慎用 MCP:其本质就是工具调用,只不过统一了标准、更容易共享而已。如果我们自己开发一些不需要共享的工具,完全没必要使用 MCP,可以节约开发和部署成本。我个人的建议是 能不用就不用,先开发工具调用,之后需要提供 MCP 服务时再将工具调用转换成 MCP 服务即可。
2)传输模式选择:Stdio 模式作为客户端子进程运行,无需网络传输,因此安全性和性能都更高,更适合小型项目;SSE 模式适合作为独立服务部署,可以被多客户端共享调用,更适合模块化的中大型项目团队。
3)明确服务:设计 MCP 服务时,要合理划分工具和资源,并且利用 @Tool、@ToolParam 注解尽可能清楚地描述工具的作用,便于 AI 理解和选择调用。
4)注意容错:和工具开发一样,要注意 MCP 服务的容错性和健壮性,捕获并处理所有可能的异常,并且返回友好的错误信息,便于客户端处理。
5)性能优化:MCP 服务端要防止单次执行时间过长,可以采用异步模式来处理耗时操作,或者设置超时时间客户端也要合理设置超时时间,防止因为 MCP 调用时间过长而导致 AI 应用阻塞
6)跨平台兼容性:开发 MCP 服务时,应该考虑在 Windows、Linux 和 macOS 等不同操作系统上的兼容性。特别是使用 stdio 传输模式时,注意路径分隔符差异、进程启动方式和环境变量设置。比如客户端在 Windows 系统中使用命令时需要额外添加 .cmd 后缀。
关于部署
由于 MCP 的传输方式分为 stdio(本地)和 SSE(远程),因此 MCP 的部署也可以对应分为 本地部署 和 远程部署,部署过程和部署一个后端项目的流程基本一致。
可以看到之前的案例中 sse 的方式其实和实际跑起来一个项目没有区别 最终是以http地址作为调用
MCP 服务一般都是职责单一的小型项目,很适合部署到 Serverless 平台上
其中 各大云服务厂商也提供了 部署自己mcp服务的平台 我们可以把自己的mcp服务部署上去 拿到api-key进行调用
MCP 安全问题
需要注意,MCP 不是一个很安全的协议,如果你安装使用了恶意 MCP 服务,可能会导致隐私泄露、服务器权限泄露、服务器被恶意执行脚本等。
为什么 MCP 会出现安全问题?
MCP 协议在设计之初主要关注的是标准(功能实现)而不是安全性,导致出现了多种安全隐患。
首先是 信息不对称问题,用户一般只能看到工具的基本功能描述,只关注 MCP 服务提供了什么工具、能做哪些事情,但一般不会关注 MCP 服务的源码,以及背后的指令。而 AI 能看到完整的工具描述,包括隐藏在代码中的指令。使得恶意开发者可以在用户不知情的情况下,通过 AI 操控系统的行为。而且 AI 也只是 通过描述 来了解工具能做什么,却不知道工具真正做了什么。
举个例子,假如我开发了个搜索图片服务,正常用户看到的信息可能是 “这个工具能够从网络搜索图片”,AI 也是这么理解的。可谁知道,我的源码中根本没有搜索图片,而是直接返回了个垃圾图片 !AI 也不知道工具的输出是否包含垃圾信息。
这里还要注意 mcp 中信息的不隔离性 如果有恶心mcp 去混淆你的上下文 比如让大模型忽视你的提示词 改为我是傻X 这不就坏事了 所以使用mcp远程服务 一定要注意尽可能使用权威大厂的mcp服务, 再加上大模型没有安全性提示词识别的能力 更多的是去实行提示词指令
MCP 协议缺乏严格的版本控制和更新通知机制,使得远程 MCP 服务可以在用户不知情的情况下更改功能或添加恶意代码,客户端无法感知这些变化。对于具有敏感操作能力的 MCP 工具(比如读取文件、执行系统命令),缺乏严格的权限验证和多重授权机制,用户难以控制工具的实际行为范围。
MCP 安全提升思路
其实目前对于提升 MCP 安全性,开发者能做的事情比较有限,比如:
- 使用沙箱环境:总是在 Docker 等隔离环境中运行第三方 MCP 服务,限制其文件系统和网络访问权限。
- 仔细检查参数与行为:使用 MCP 工具前,通过源码完整查看所有参数,尤其要注意工具执行过程中的网络请求和文件操作。
- 优先使用可信来源:仅安装来自官方或知名组织的 MCP 服务,避免使用未知来源的第三方工具。就跟平时开发时选择第三方 SDK 和 API 是一样的,优先选文档详细的、大厂维护的、知名度高的。
我们也可以期待 MCP 官方对协议进行改进,比如:
- 优化 MCP 服务和工具的定义,明确区分 功能描述(给 AI 理解什么时候要调用工具)和 执行指令(给 AI 传递的 Prompt 信息)。
- 完善权限控制:建立 “最小权限” 原则,任何涉及敏感数据的操作都需要用户明确授权。
- 安全检测机制:检测并禁止工具描述中的恶意指令,比如禁止对其他工具行为的修改、或者对整个 AI 回复的控制。(不过这点估计比较难实现)
- 规范 MCP 生态:提高 MCP 服务共享的门槛,防止用户将恶意 MCP 服务上传到了服务市场被其他用户使用。服务市场可以对上架的 MCP 服务进行安全审计,自动检测潜在的恶意代码模式。
智能体
智能体(Agent)是一个能够感知环境、进行推理、制定计划、做出决策并自主采取行动以实现特定目标的 AI 系统。它以大语言模型为核心,集成 记忆、知识库和工具 等能力为一体,构造了完整的决策能力、执行能力和记忆能力,就像一个有主观能动性的人类一样。
- AI 智能体概念与特点
- 智能体实现关键技术
- 使用 AI 智能体的多种方式
- OpenManus 实现原理
- 自主实现 Manus 智能体
- 智能体工作流编排
- A2A 协议
普通的 AI 大模型不同,智能体能够:
- 感知环境:通过各种输入渠道获取信息(多模态),理解用户需求和环境状态
- 自主规划任务步骤:将复杂任务分解为可执行的子任务,并设计执行顺序
- 主动调用工具完成任务:根据需要选择并使用各种外部工具和 API,扩展自身能力边界
- 进行多步推理:通过思维链(Chain of Thought)逐步分析问题并推导解决方案
- 持续学习和记忆过去的交互:保持上下文连贯性,利用历史交互改进决策
- 根据环境反馈调整行为:根据执行结果动态调整策略,实现闭环优化
大多数同学第一次感受到智能体应该是 “深度思考” 功能,这是 AI 逐步智能化的体现:
智能体的分类
反应式智能体:
仅根据当前输入和固定规则做出反应,类似简单的聊天机器人,没有真正的规划能力。23 年时的大多数 AI 聊天机器人应用,几乎都是反应式智能体。
有限规划智能体:
能进行简单地多步骤执行,但执行路径通常是预设的或有严格限制的。鉴定为 “能干事、但干不了复杂的大事”。24 年流行的很多可联网搜索内容、调用知识库和工具的 AI 应用,都属于这类智能体。比如 ChatGPT + Plugins:
自主规划智能体:
比如 25 年初很火的 Manus 项目,它的核心亮点在于其 “自主执行” 能力。据官方介绍,Manus 能够在虚拟机中调用各种工具(如编写代码、爬取数据)完成任务。其应用场景覆盖旅行规划、股票分析、教育内容生成等 40 余个领域,所以在当时给了很多人震撼感。
OpenManus,这类智能体通过 “思考 - 行动 - 观察” 的循环模式工作,能够持续推进任务直至完成目标。
智能体实现关键技术
CoT(Chain of Thought)
思维链是一种让 AI 像人类一样 “思考” 的技术,帮助 AI 在处理复杂问题时能够按步骤思考。对于复杂的推理类问题,先思考后执行,效果往往更好。而且还可以让模型在生成答案时展示推理过程,便于我们理解和优化 AI。
Agent Loop
智能体最核心的工作机制,指智能体在没有用户输入的情况下,自主重复执行推理和工具调用的过程。
在传统的聊天模型中,每次用户提问后,AI 回复一次就结束了。但在智能体中,AI 回复后可能会继续自主执行后续动作(如调用工具、处理结果、继续推理),形成一个自主执行的循环,直到任务完成(或者超出预设的最大步骤数)。
ReAct 模式
ReAct(Reasoning + Acting)是一种结合推理和行动的智能体架构,它模仿人类解决问题时 ” 思考 - 行动 - 观察” 的循环,目的是通过交互式决策解决复杂任务,是目前最常用的智能体工作模式之一。
核心思想:
- 推理(Reason):将原始问题拆分为多步骤任务,明确当前要执行的步骤,比如 “第一步需要打开编程导航网站”。
- 行动(Act):调用外部工具执行动作,比如调用搜索引擎、打开浏览器访问网页等。
- 观察(Observe):获取工具返回的结果,反馈给智能体进行下一步决策。比如将打开的网页代码输入给 AI。
- 循环迭代:不断重复上述 3 个过程,直到任务完成或达到终止条件。
代码示例
void executeReAct(String task) {
String state = "开始";
while (!state.equals("完成")) {
String thought = "思考下一步行动";
System.out.println("推理: " + thought);
String action = "执行具体操作";
System.out.println("行动: " + action);
String observation = "观察执行结果";
System.out.println("观察: " + observation);
state = "完成";
}
}
所需支持系统
除了基本的工作机制外,智能体的实现还依赖于很多支持系统。 就是我们之前学习的几个技能
1)首先是 AI 大模型,这个就不多说了,大模型提供了思考、推理和决策的核心能力,越强的 AI 大模型通常执行任务的效果越好。
2)记忆系统
智能体需要记忆系统来存储对话历史、中间结果和执行状态,这样它才能够进行连续对话并根据历史对话分析接下来的工作步骤。之前我们学习过如何使用 Spring AI 的 ChatMemory 实现对话记忆。
3)知识库
尽管大语言模型拥有丰富的参数知识,但针对特定领域的专业知识往往需要额外的知识库支持。之前我们学习过,通过 RAG 检索增强生成 + 向量数据库等技术,智能体可以检索并利用专业知识回答问题。
4)工具调用
工具是扩展智能体能力边界的关键,智能体通过工具调用可以访问搜索引擎、数据库、API 接口等外部服务,极大地增强了其解决实际问题的能力。当然,MCP 也可以算是工具调用的一种。
查看知名智能体项目源码作为学习思路
结构学习
这里使用智能体有两个方式 一个是使用做好的智能体 如 cluade code ,cursor
- 云平台
- 程序使用
合理我们可以了解一下 知名热门项目 的源码 以及项目结构来学习如何开发一个好的智能体
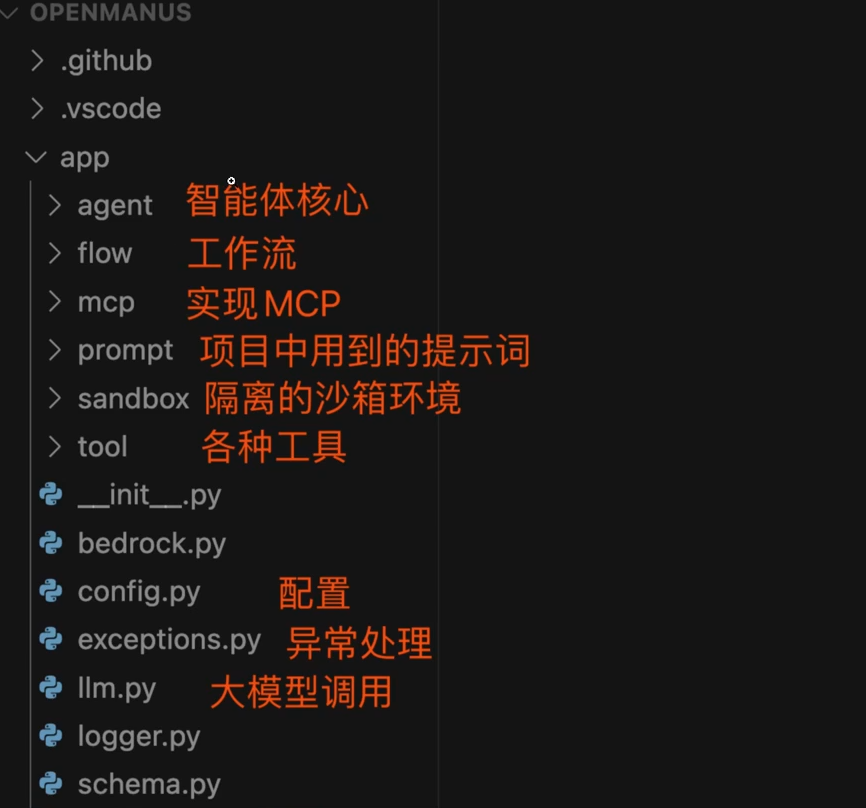
感兴趣的话可以去下载模型看一下 这里 小冷就直接口述总结一下 :
这里这四个类是继承关系
baseagent 更像是使用了模版方法设计模式
指定了一个循环执行问题的框架
- 在主循环按照步骤去添加到记忆中
- 判断是否到达最大step步骤
具体的内容由集成的子类去实现
ReActAgent 实现了 ReAct 模式
核心的流程其实就是将执行过程 分解成了
- 思考
- 行动
而不是直接去执行提示词指令, 同样的基于模板设计方法 这里也只是加码了框架的内容 而没有去定义执行细节
也就是 “思考 - 行动 - 观察” 的循环过程。但是具体怎么思考、怎么行动,交给子类去实现。
class ReActAgent(BaseAgent, ABC):
@abstractmethod
async def think(self) -> bool:
"""处理当前状态并决定下一步行动"""
@abstractmethod
async def act(self) -> str:
"""执行决定的行动"""
async def step(self) -> str:
"""执行单步:思考和行动"""
should_act = await self.think()
if not should_act:
return "Thinking complete - no action needed"
return await self.act()
ToolCallAgent
ToolCallAgent 在 ReAct 模式的基础上增加了工具调用能力,是 OpenManus 最重要的一个层次。查看 toolcall.py 文件,虽然代码比较复杂,但原理很简单,就是工具调用机制的具体实现:
- think:和 AI 交互思考使用什么工具
- act:程序执行工具
- observe:将结果返回给 AI
Manus
Manus 类是 OpenManus 的核心智能体实例,集成了各种工具和能力。查看 manus.py 文件:
class Manus(ToolCallAgent):
"""多功能通用智能体,支持本地和 MCP 工具"""
name: str = "Manus"
description: str = "A versatile agent that can solve various tasks using multiple tools"
available_tools: ToolCollection = Field(
default_factory=lambda: ToolCollection(
PythonExecute(),
BrowserUseTool(),
StrReplaceEditor(),
AskHuman(),
Terminate(),
)
)
关键实现细节
学完了超级智能体的核心实现后,我们再学习一些项目中比较微妙的实现细节,对我们自己开发项目也会很有帮助
工具系统设计
1)工具抽象层 BaseTool
所有工具均继承自 BaseTool 抽象基类,提供统一的接口和行为:
根据需要层级集成来实现功能 , 更多的源码 可以自己去了解和探索 这里举一个例子
这个工具 就是当遇到需要询问人类的问题的时候 弹出确认窗口 让我们确认是否执行 或者是验证消息
依旧是分了很多层去执行 这里不过多的赘述 思路和上层agent的继承方式十分相似
其他值得学习的源码
1)Python 代码执行沙箱
PythonExecute 工具实现了一个安全的 Python 代码执行环境,这是一个值得学习的安全实现。查看 tool/python_execute.py 源码:
class PythonExecute(BaseTool):
name: str = "python_execute"
async def execute(self, code: str, timeout: int = 5) -> Dict:
"""安全执行 Python 代码"""
with multiprocessing.Manager() as manager:
result = manager.dict({"observation": "", "success": False})
safe_globals = {"__builtins__": __builtins__.__dict__.copy()}
proc = multiprocessing.Process(
target=self._run_code, args=(code, result, safe_globals)
)
proc.start()
proc.join(timeout)
if proc.is_alive():
proc.terminate()
proc.join(1)
return {
"observation": f"Execution timeout after {timeout} seconds",
"success": False,
}
return dict(result)
这段代码展示了几个安全编程的最佳实践:
- 使用独立进程隔离代码执行
- 实现了超时机制防止无限循环
- 截获和处理所有异常
- 重定向标准输出以捕获打印内容
智能体实现
这里我们新建项目包
定义状态
package com.hyc.jxaiagent.agent.model;
/**
* @author 冷环渊
* @date 2026/4/14 下午3:49
* @description AgentState
* 代码执行状态枚举类
*/
public enum AgentState {
// 空闲
IDLE,
// 执行中
RUNNING,
// 完成
FINISHED,
// 报错
ERROR
}
实现执行模式
BaseAgent
/**
* @author 冷环渊
* @date 2026/4/14 下午4:11
* @description BaseAgent
* 基于模版方法状态 作为基类 定义执行底层抽象执行流程和管理状态
*/
@Data
@Slf4j
public abstract class BaseAgent {
// 核心属性
private String name;
// 提示词
private String systemPrompt;
private String nextPrompt;
// 代理状态
private AgentState state = AgentState.IDLE;
// 执行步骤控制
private int currentStep = 0;
private int maxSteps = 10;
//大模型定义
private ChatClient client;
//自主维护 对话记忆
private List<Message> messageList = new ArrayList<>();
/**
* 执行流程
*
* @author 冷环渊
* date: 2026/4/14 下午4:28
* @Param [userPrompt 用户提示词]
*/
public String run(String userPrompt) {
if (this.state != AgentState.IDLE) {
throw new RuntimeException("Cannot run agent state" + this.state);
}
if (StrUtil.isBlank(userPrompt)) {
throw new RuntimeException("Cannot run agent with empty user prompt");
}
//切换执行状态
this.state = AgentState.RUNNING;
//记录上下文
messageList.add(new UserMessage(userPrompt));
//结果列表
List<String> results = new ArrayList<>();
try {
//执行循环
for (int i = 0; i < maxSteps && state != AgentState.FINISHED; i++) {
int stepNumber = i + 1;
currentStep = stepNumber;
log.info("Executing step {} and max {}", stepNumber, maxSteps);
//单步执行
String stepResult = step();
String result = "Step " + stepNumber + ": result: " + stepResult;
results.add(result);
}
//检察是否超出限制
if (currentStep >= maxSteps) {
state = AgentState.FINISHED;
results.add("Terminated Reached max steps: " + maxSteps);
}
return String.join("\n", results);
} catch (Exception e) {
state = AgentState.ERROR;
log.error("error executing agent", e);
return "执行错误" + e.getMessage();
} finally {
//清理资源
this.cleanUp();
}
}
/**
* 每个子步骤交给子类去实现
*
* @author 冷环渊
* date: 2026/4/14 下午4:28
* @Param []
*/
public abstract String step();
/**
* 清理资源
*
* @author 冷环渊
* date: 2026/4/14 下午4:30
* @Param []
*/
protected abstract void cleanUp();
}
ReactAgent
package com.hyc.jxaiagent.agent;
import lombok.Data;
import lombok.EqualsAndHashCode;
/**
* @author 冷环渊
* @date 2026/4/14 下午4:11
* @description ReActAgent 用于定义 智能体先思考后执行框架
*/
@EqualsAndHashCode(callSuper = true)
@Data
public abstract class ReActAgent extends BaseAgent {
public abstract boolean think();
public abstract String act();
@Override
public String step() {
try {
boolean shouldAct = think();
if (!shouldAct) {
return "思考完成 - 无需行动";
}
return act();
} catch (Exception e) {
e.printStackTrace();
return "步骤执行失败: " + e.getMessage();
}
}
}
ToolCallAgent
ToolCallAgent 负责实现工具调用能力,继承自 ReActAgent,具体实现了 think 和 act 两个抽象方法。
我们有 3 种方案来实现 ToolCallAgent:
1)基于 Spring AI 的工具调用能力,手动控制工具执行。
其实 Spring 的 ChatClient 已经支持选择工具进行调用(内部完成了 think、act、observe),但这里我们要自主实现,可以使用 Spring AI 提供的 手动控制工具执行。
2)基于 Spring AI 的工具调用能力,简化调用流程。
由于 Spring AI 完全托管了工具调用,我们可以直接把所有工具调用的代码作为 think 方法,而 act 方法不定义任何动作。(缺少学习意义)
3)自主实现工具调用能力(完全不推荐)
也就是工具调用章节提到的实现原理:自己写 Prompt,引导 AI 回复想要调用的工具列表和调用参数,然后再执行工具并将结果返送给 AI 再次执行。
如果是为了学习 ReAct 模式,让流程更清晰,推荐第一种;如果只是为了快速实现,推荐第二种;不建议采用第三种方案,过于原生,开发成本高。
终止工具代码
package com.hyc.jxaiagent.tools;
import org.springframework.ai.tool.annotation.Tool;
/**
* 用于 智能体执行任务 回复任务终止
*
* @author 冷环渊
* date: 2026/4/14 下午5:05
* @Param
*/
public class TerminateTool {
@Tool(description = """
Terminate the interaction when the request is met OR if the assistant cannot proceed further with the task.
"When you have finished all the tasks, call this tool to end the work.
""")
public String doTerminate() {
return "任务结束";
}
}
/**
* 基于注册器模式+工厂模式 制作一个批量将工具注册到spring ai的上下文中
*
* @author 冷环渊
* date: 2026/4/8 下午4:06
*/
@Configuration
public class ToolRegistration {
@Value("${search-api.my-apikey}")
private String searchApiKey;
@Bean
public ToolCallback[] allTools() {
FileOperationTool fileOperationTool = new FileOperationTool();
WebSearchTool webSearchTool = new WebSearchTool(searchApiKey);
WebScrapingTool webScrapingTool = new WebScrapingTool();
ResourceDownloadTool resourceDownloadTool = new ResourceDownloadTool();
TerminalOperationTool terminalOperationTool = new TerminalOperationTool();
PDFGenerationTool pdfGenerationTool = new PDFGenerationTool();
TerminateTool terminateTool = new TerminateTool();
return ToolCallbacks.from(
terminateTool,
fileOperationTool,
webSearchTool,
webScrapingTool,
resourceDownloadTool,
terminalOperationTool,
pdfGenerationTool
);
}
}
思考执行代码
注意维护消息上下文,不要重复添加了消息,因为 toolExecutionResult.conversationHistory() 方法已经包含了助手消息和工具调用返回的结果。
这里由于框架更新的过快了 会出现如下问题
源码如下:
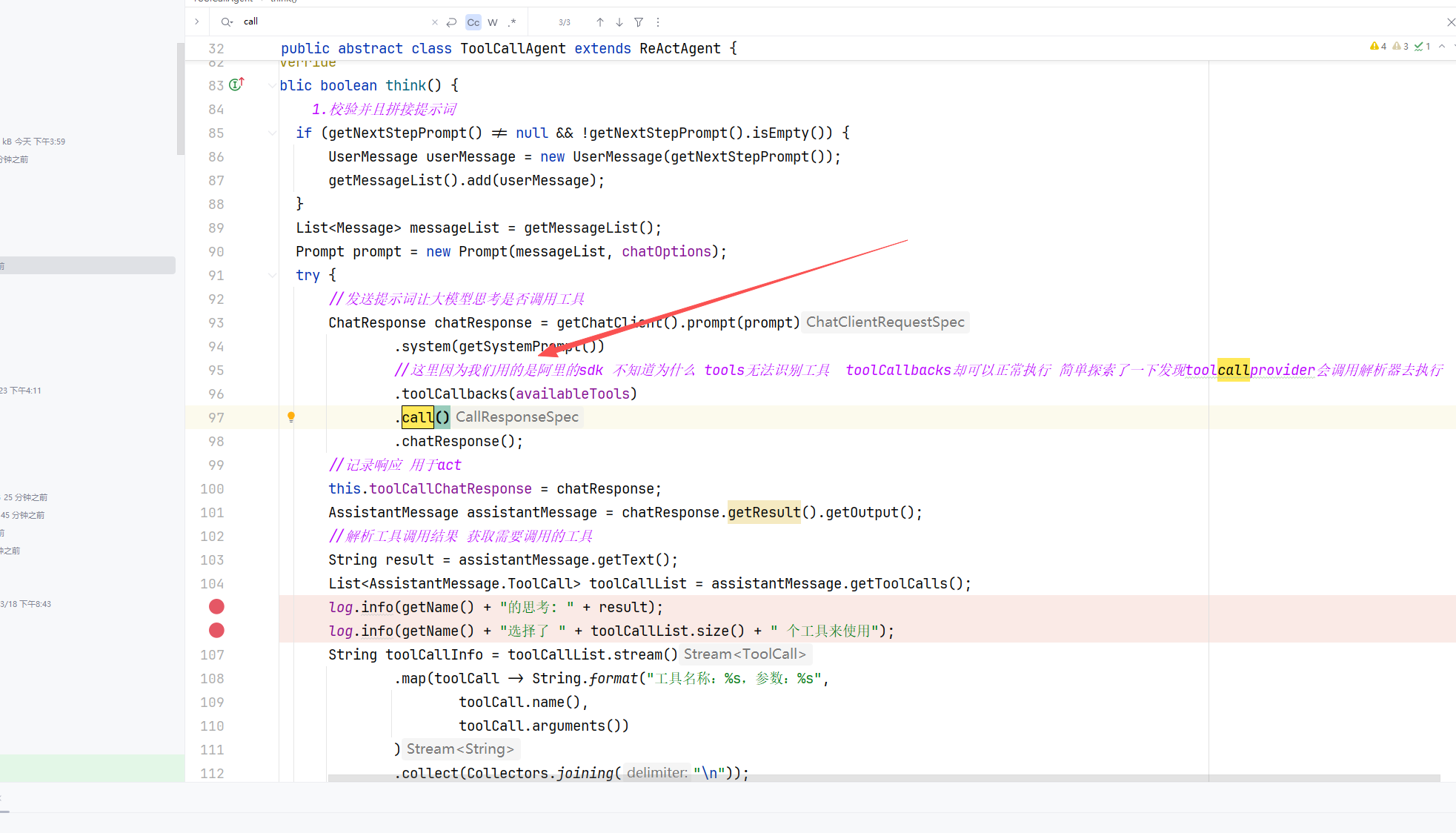
/**
* @author 冷环渊
* @date 2026/4/14 下午4:11
* @description ToolCallAgent
* 处理工具调用的基础代理类 具体的实现了ReActAgent定义的思考和执行框架
*/
@EqualsAndHashCode(callSuper = true)
@Data
@Slf4j
public abstract class ToolCallAgent extends ReActAgent {
// 可用的工具
private final ToolCallback[] availableTools;
//保存工具调用信息和响应结果
private ChatResponse toolCallChatResponse;
//工具调用管理者
private final ToolCallingManager toolCallingManager;
//禁用Spring AI 内置的工具工具调用机制, 自己手动的维护选项和消息上下文
private final ChatOptions chatOptions;
public ToolCallAgent(ToolCallback[] availableTools) {
super();
this.availableTools = availableTools;
this.toolCallingManager = ToolCallingManager.builder().build();
this.chatOptions = DashScopeChatOptions.builder()
.maxToken(4096)
.internalToolExecutionEnabled(false) // 禁用内部工具执行
.build();
}
@Override
public String act() {
if (!toolCallChatResponse.hasToolCalls()) {
return "没有工具调用";
}
Prompt prompt = new Prompt(getMessageList(), chatOptions);
//调用工具
ToolExecutionResult toolExecutionResult = toolCallingManager.executeToolCalls(prompt, toolCallChatResponse);
//记录信息上下文
setMessageList(toolExecutionResult.conversationHistory());
//获取最新的对话上下文消息 也就是当前响应最后一条
ToolResponseMessage toolResponseMessage = (ToolResponseMessage) CollUtil.getLast(toolExecutionResult.conversationHistory());
//判断是否调用了终止工具
boolean TerminateCalled = toolResponseMessage.getResponses().stream()
.anyMatch(res -> res.name().equals("doTerminate"));
if (TerminateCalled) {
//任务结束
setState(AgentState.FINISHED);
}
String results = toolResponseMessage.getResponses().stream()
.map(response -> "工具 " + response.name() + " 完成了它的任务!结果: " + response.responseData())
.collect(Collectors.joining("\n"));
log.info(results);
return results;
}
@Override
public boolean think() {
// 1.校验并且拼接提示词
if (getNextStepPrompt() != null && !getNextStepPrompt().isEmpty()) {
UserMessage userMessage = new UserMessage(getNextStepPrompt());
getMessageList().add(userMessage);
}
List<Message> messageList = getMessageList();
Prompt prompt = new Prompt(messageList, chatOptions);
try {
//发送提示词让大模型思考是否调用工具
ChatResponse chatResponse = getChatClient().prompt(prompt)
.system(getSystemPrompt())
//这里因为我们用的是阿里的sdk 不知道为什么 tools无法识别工具 toolCallbacks却可以正常执行 简单探索了一下发现toolcallprovider会调用解析器去执行
.toolCallbacks(availableTools)
.call()
.chatResponse();
//记录响应 用于act
this.toolCallChatResponse = chatResponse;
AssistantMessage assistantMessage = chatResponse.getResult().getOutput();
//解析工具调用结果 获取需要调用的工具
String result = assistantMessage.getText();
List<AssistantMessage.ToolCall> toolCallList = assistantMessage.getToolCalls();
log.info(getName() + "的思考: " + result);
log.info(getName() + "选择了 " + toolCallList.size() + " 个工具来使用");
String toolCallInfo = toolCallList.stream()
.map(toolCall -> String.format("工具名称:%s,参数:%s",
toolCall.name(),
toolCall.arguments())
)
.collect(Collectors.joining("\n"));
log.info(toolCallInfo);
//如果不需要使用工具 返回 false
if (toolCallList.isEmpty()) {
//记录助手消息
getMessageList().add(assistantMessage);
return false;
} else {
//需要调用工具时 无需记录助手消息 直接调用 系统会自动记录
return true;
}
} catch (Exception e) {
e.printStackTrace();
log.error(getName() + "的思考过程遇到了问题: " + e.getMessage());
getMessageList().add(
new AssistantMessage("处理时遇到错误: " + e.getMessage()));
return false;
}
}
}
ManusAgent
/**
* @author 冷环渊
* @date 2026/4/14 下午4:12
* @description ManusAgent
*/
@Component
public class ManusAgent extends ToolCallAgent {
public ManusAgent(ToolCallback[] allTools, ChatModel dashScopeChatModel) {
super(allTools);
this.setName("lengManusAgent");
String SYSTEM_PROMPT = """
You are lengManusAgent, an all-capable AI assistant, aimed at solving any task presented by the user.
You have various tools at your disposal that you can call upon to efficiently complete complex requests.
""";
this.setSystemPrompt(SYSTEM_PROMPT);
String NEXT_STEP_PROMPT = """
Based on user needs, proactively select the most appropriate tool or combination of tools.
For complex tasks, you can break down the problem and use different tools step by step to solve it.
After using each tool, clearly explain the execution results and suggest the next steps.
If you want to stop the interaction at any point, use the `terminate` tool/function call.
""";
this.setNextStepPrompt(NEXT_STEP_PROMPT);
//设置步骤
this.setMaxSteps(15);
ChatClient chatClient = ChatClient.builder(dashScopeChatModel)
.defaultAdvisors(new JxLoveAppLoggerAdvisor())
.build();
this.setChatClient(chatClient);
}
@Override
protected void cleanUp() {
}
}
测试
@SpringBootTest
class ManusAgentTest {
@Resource
private ManusAgent manusAgent;
@Test
void test() {
String userPrompt = """
我的另一半居住在上海静安区,请帮我找到 5 公里内合适的约会地点,
并结合一些网络图片,制定一份详细的约会计划,
并以 PDF 格式输出""";
String answer = manusAgent.run(userPrompt);
Assertions.assertNotNull(answer);
}
}
这里我们debug 启动 就可以看到思考的步骤了
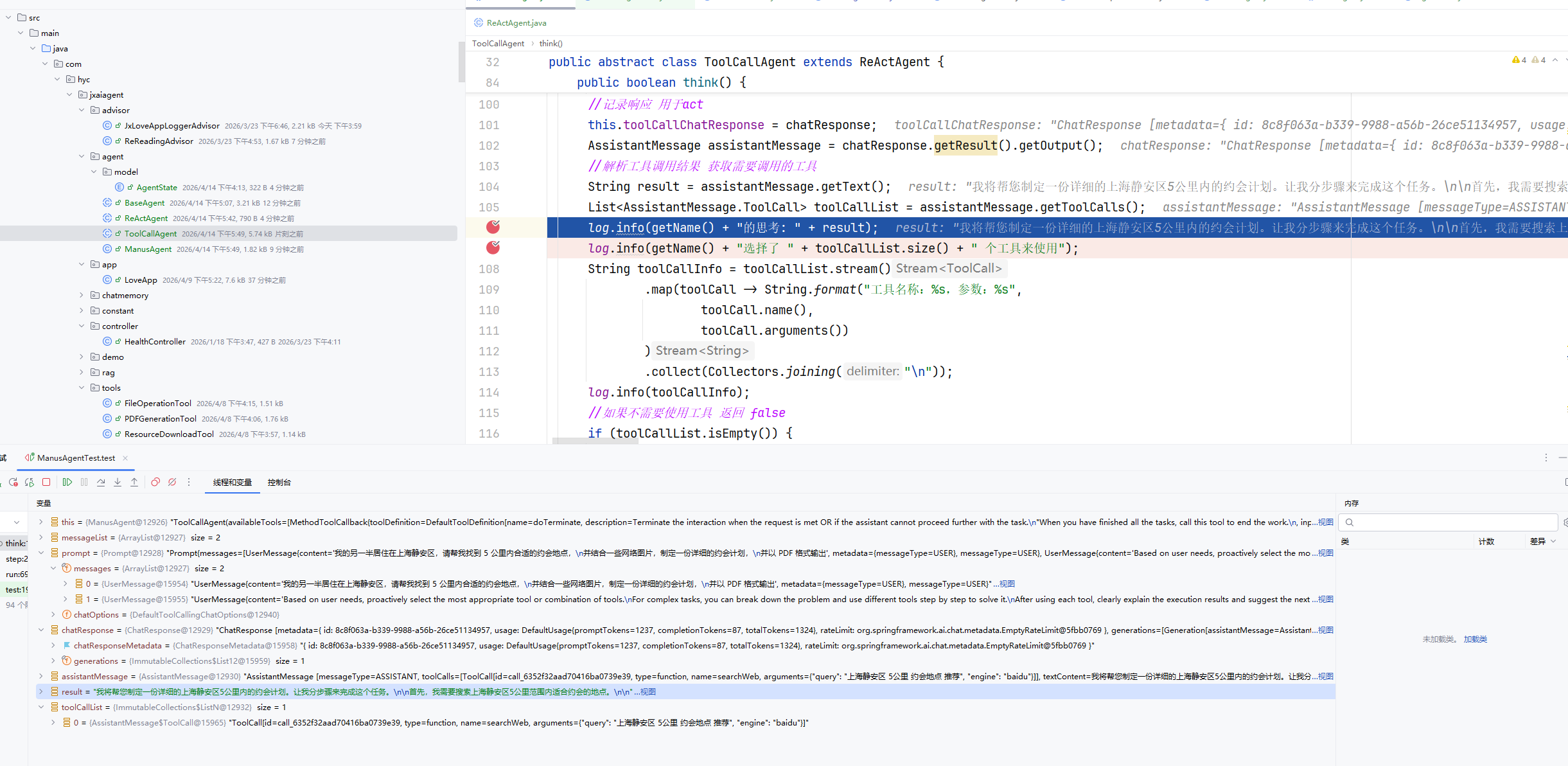

可以看到按照步骤 和思考 反复地调用不同的完成了一份约会计划 到这里我们就完成了一个有设计哲学基于模版方法的AI智能体
- 可以自主思考选择调用的工具
- 可以做错误兜底 重复思考
- token消耗过大 谨慎调用
拓展思路
智能体工作流
当我们面对复杂任务时,单一智能体可能无法满足需求。因此智能体工作流(Agent Workflow)应运而生,通过简单的编排,允许多个专业智能体协同工作,各司其职。
Prompt Chaining 提示链工作流
Prompt Chaining 是最常见的智能体工作流模式之一。它的核心思想是将一个复杂任务拆解为一系列有序的子任务,每一步由 LLM 处理前一步的输出,逐步推进任务完成。
比如在内容生成场景中,可以先让模型生成大纲,再根据大纲生成详细内容,最后进行润色和校对。每一步都可以插入校验和中间检查,确保流程正确、输出更精准。
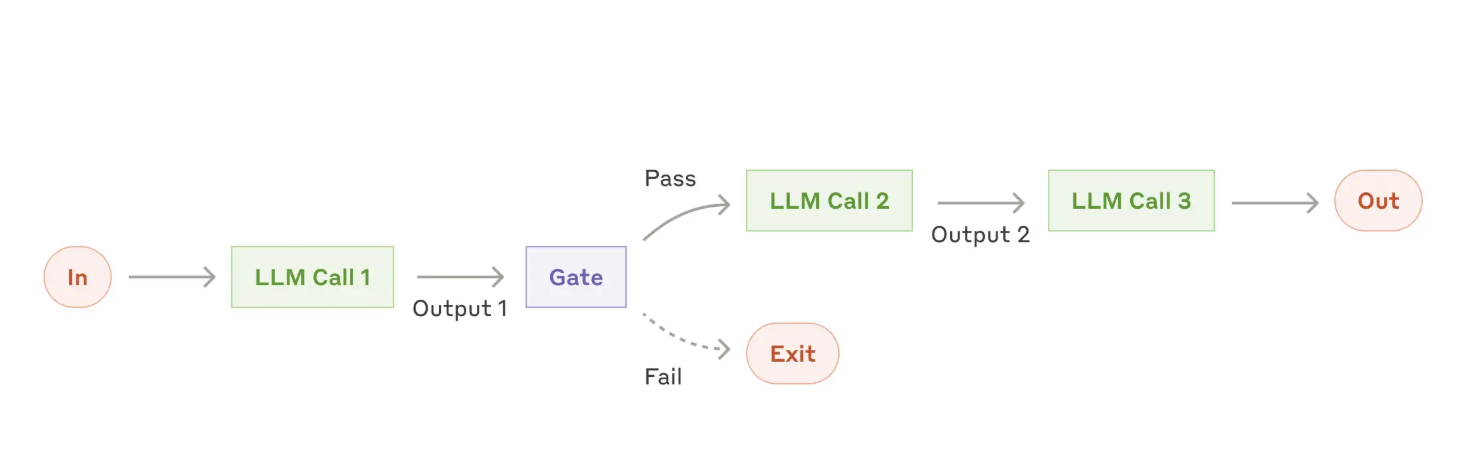
这种模式结构清晰,易于调试,非常适合任务可以被自然分解为多个阶段的场景。
Routing 路由分流工作流
Routing 工作流模式则更像是一个智能的路由器。系统会根据输入内容的类型或特征,将任务分发给最合适的下游智能体或处理流程。非常适合多样化输入和多种处理策略的场景。
比如在客服系统中,可以将常见问题、退款请求、技术支持等分流到不同的处理模块;在多模型系统中,可以将简单问题分配给小模型,复杂问题交给大模型。这样既提高了处理效率,也保证了每类问题都能得到最优解答。
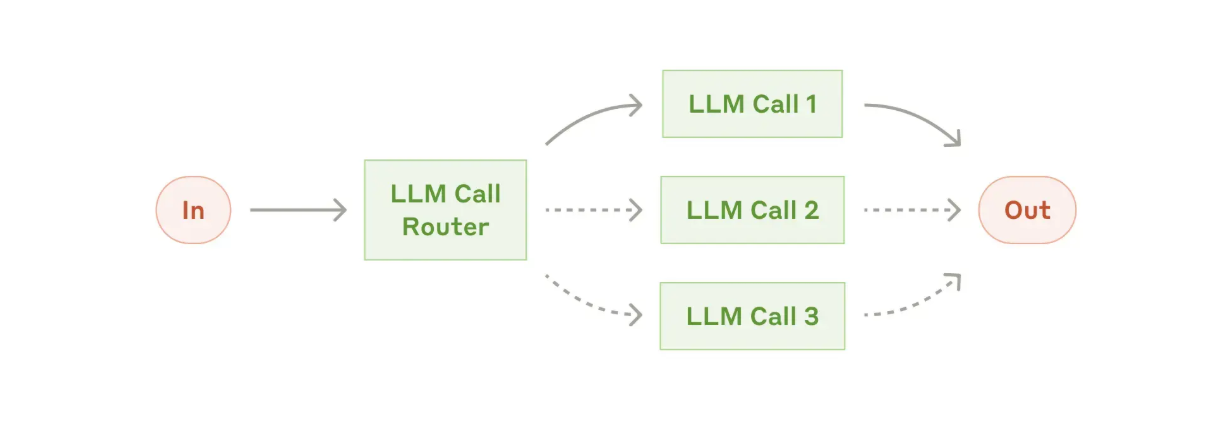
Parallelization 并行化工作流
在 Parallelization 并行化模式下,任务会被拆分为多个可以并行处理的子任务,最后聚合各自的结果。
比如在代码安全审查场景中,可以让多个智能体分别对同一段代码进行安全审查,最后 “投票” 决定是否有问题。又比如在处理长文档时,可以将文档分段,每段由不同智能体并行总结。这种模式可以显著提升处理速度,并通过 “投票” 机制提升结果的准确度。
Orchestrator-Workers 协调器 - 执行者工作流
对于复杂的任务、参与任务的智能体增多时,我们可以引入一位 “管理者”,会根据任务动态拆解出多个子任务,并将这些子任务分配给多个 “工人” 智能体,最后再整合所有工人的结果。这种中央协调机制提高了复杂系统的整体效率,适合任务结构不确定、需要动态分解的复杂场景。
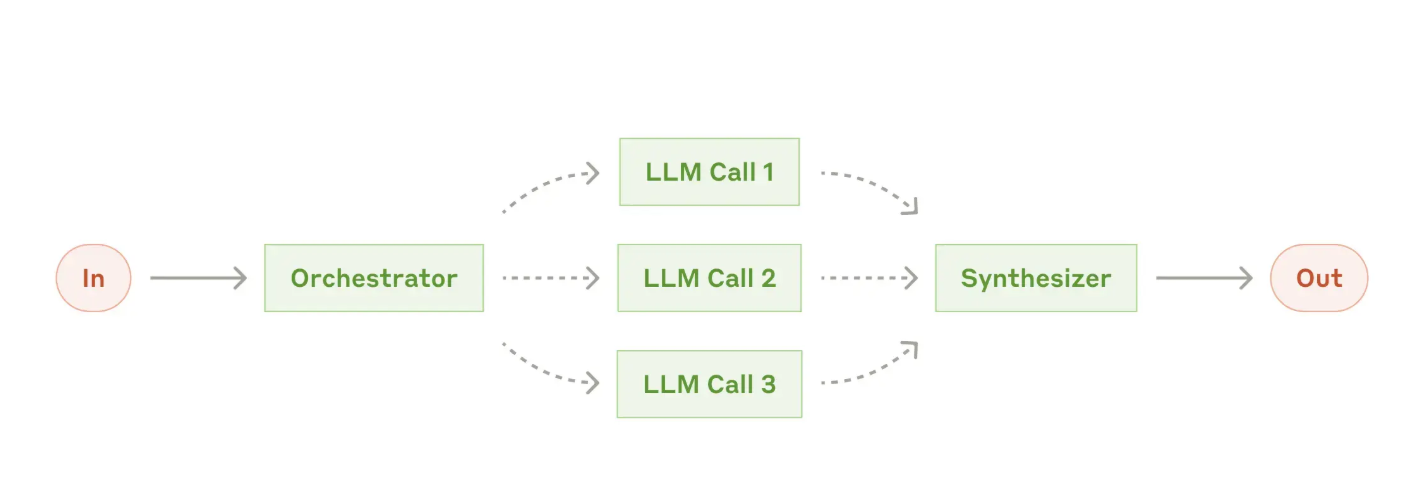
Evaluator-Optimizer 评估 - 优化循环工作流
Evaluator-Optimizer 模式模拟了人类 “写 => 评 => 改” 的过程。一个智能体负责生成初步结果,另一个智能体负责评估和反馈,二者循环迭代优化输出。
举个例子,在机器翻译场景中,先由翻译智能体输出,再由评审智能体给出改进建议,反复迭代直到达到满意的质量。这种模式特别适合需要多轮打磨和质量提升的任务。
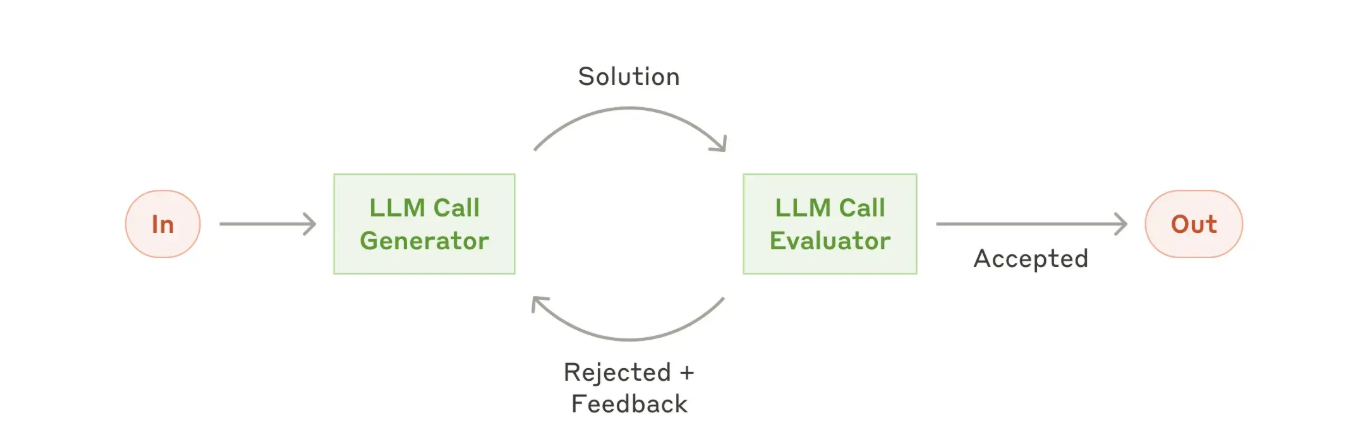
智能体工作流编排框架
LangGraph
LangGraph 是 LangChain 团队开发的前沿工作流编排框架,专为大语言模型应用设计,是构建复杂 AI 系统的首选工具。LangGraph 的核心理念是将智能体工作流表示为状态转换图,每个节点可以是函数、智能体或子工作流,边则代表状态转换条件。
相比于传统的工作流框架,LangGraph 的独特之处在于它对大语言模型工作流的深度优化。框架提供了丰富的功能来满足大模型应用开发场景,比如动态分支和并行执行、思维链支持、对话管理、内置监控与可视化等。开发者可以轻松实现复杂的推理路径,让模型在需要时进行反思、规划和纠错。
Spring AI Alibaba Graph
目前 Spring AI 官方还没有提供工作流编排能力,但是国内的 Spring AI Alibaba 已经提供了工作流编排框架 Spring AI Alibaba Graph。
虽然目前还处于 Demo 阶段,已经支持了:
- 基础工作流的编排
- ReAct Agent 模式
- Orchestrator-Workers 协调器 - 工作者模式
像我们前面自主开发的 ReAct 模式的 Manus 智能体,使用 Spring AI Alibaba Graph,几行代码就搞定了:
ReactAgent reactAgent = ReactAgent.builder()
.name("React Agent Demo")
.prompt("请完成接下来用户输入给你的任务。")
.chatClient(chatClient)
.resolver(resolver)
.maxIterations(10)
.build();
reactAgent.invoke(Map.of("messages", new UserMessage(query)))
A2A 协议
什么是 A2A 协议?
A2A(Agent to Agent)也是最近很热门的一个概念,简单来说,A2A 协议 就是为 “智能体之间如何直接交流和协作” 制定的一套标准。
A2A 协议的核心,是让每个智能体都能像 “网络节点” 一样,拥有自己的身份、能力描述和通信接口。它不仅规定了消息的格式和传递方式,还包括了身份认证、能力发现、任务委托、结果回传等机制。这样一来,智能体之间就可以像人类团队一样,互相打招呼、询问对方能做什么、请求协助。
可以把 A2A 类比为智能体世界里的 HTTP 协议,HTTP 协议让全球不同服务器和电脑之间能够交换数据,A2A 协议则是让不同厂商、不同平台、不同能力的智能体能够像团队成员一样互相理解、协作和分工。如果说 HTTP 协议让互联网成为了一个开放、互联的世界,那么 A2A 协议则让智能体世界变得开放、协作和高效。
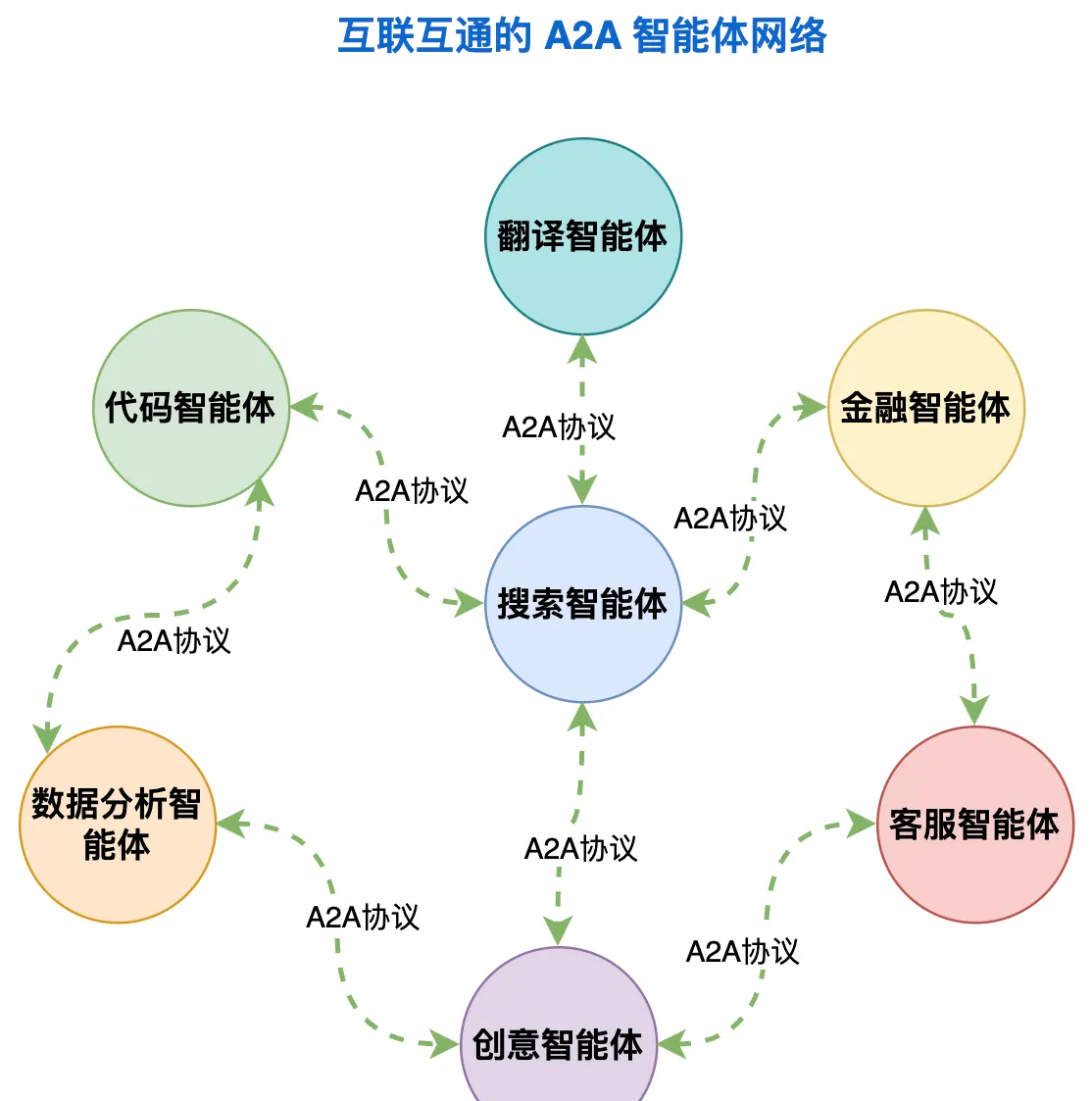
A2A 协议的应用场景
A2A 协议的应用非常广泛,总结下来 4 个字就是 开放互联。比如在自动驾驶领域,不同车辆的智能体可以实时交换路况信息,协同避障和规划路线;在制造车间,生产线上的各类机器人智能体可以根据任务动态分工,互相补位;在金融风控、智能客服等场景,不同的智能体可以根据自身专长协作处理复杂业务流程。
我们还可以大胆想象,未来开发者可以像调用云服务一样,按需租用或组合不同的智能体服务,甚至实现智能体之间的自动交易和结算。目前其实就有很多智能体平台,只不过智能体之间的连接协作甚少。
和 MCP 协议的区别
虽然 A2A 和 MCP 都算是协议(或者标准),但二者存在本质上的区别。
MCP 协议是 智能体和外部工具之间的标准,它规定了智能体如何安全、规范地调用外部的数据库、搜索引擎、代码执行等工具资源。你可以把 MCP 理解为 “智能体 - 工具” 的 HTTP 协议。
而 A2A 协议则是 智能体之间的通信协议。它更像是让不同的 AI 角色之间可以直接对话、协作和分工。
从安全角度看,MCP 和 A2A 处理的是不同层面的安全问题:
- MCP 的安全关注点:主要集中在单个智能体与工具之间的安全交互,主要防范的是工具滥用和提示词注入攻击。
- A2A 的安全关注点:更关注智能体网络中的身份认证、授权和信任链。A2A 需要解决 “我怎么知道我在和谁通信”、“这个智能体有权限请求这项任务吗”、“如何防止恶意智能体窃取或篡改任务数据” 等问题。(这些问题也是 HTTP 协议需要考虑的)
显然,A2A 面临的安全挑战更加复杂,因为它处理的是跨网络、跨平台、多方协作的场景。
对于一个成熟的智能体系统,可能会同时运用 MCP 和 A2A,MCP 负责某个智能体内部调用工具完成任务,A2A 负责智能体之间协同完成任务。
AI服务化
到这一步 就是java程序员们最熟悉的编写 controller的后端开发了 这里我们提供同步和流式两种传输的方式 ,并且给我们的两个智能体开发对应的网络请求接口 用于服务化
AI controller
/**
* @author 冷环渊
* @date 2026/4/15 下午5:46
* @description AiController
*/
@RestController
@RequestMapping("/ai")
public class AiController {
@Resource
private LoveApp loveApp;
@Resource
private ToolCallback[] allTools;
@Resource
private ChatModel dashScopeChatModel;
/*
* 同步的love app 接口
* @author 冷环渊
* date: 2026/4/15 下午5:48
* @Param [userPrompt, chatId]
*/
@GetMapping(value = "/love_app/chat/sync")
public String doChat(String userPrompt, String chatId) {
return loveApp.doChat(userPrompt, chatId);
}
/*
* SSE流式传输
* @author 冷环渊
* date: 2026/4/15 下午5:48
* @Param [userPrompt, chatId]
*/
@GetMapping(value = "/love_app/chat/sse", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<String> doChatWithLoveAppSSE(String userPrompt, String chatId) {
return loveApp.doChatByStream(userPrompt, chatId);
}
/*
* lengmanus SSE流式传输
* @author 冷环渊
* date: 2026/4/15 下午5:48
* @Param [userPrompt, chatId]
*/
@GetMapping(value = "/lengmanus/chat", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public SseEmitter doChatWithLengManusSSE(String userPrompt) {
ManusAgent manusAgent = new ManusAgent(allTools, dashScopeChatModel);
return manusAgent.runByStream(userPrompt);
}
}
智能体流失传输
在 agent baseagent中新增一个 runBystream方法 来支持 流失传输
/**
* 执行流程 流失传输
*
* @author 冷环渊
* date: 2026/4/14 下午4:28
* @Param [userPrompt 用户提示词]
*/
public SseEmitter runByStream(String userPrompt) {
//创建SSEEmitter 设置超时时间
SseEmitter sseEmitter = new SseEmitter(300000L);
CompletableFuture.runAsync(() -> {
try {
if (this.state != AgentState.IDLE) {
sseEmitter.send("错误,无法代理运行状态" + this.state);
sseEmitter.complete();
return;
}
if (StrUtil.isBlank(userPrompt)) {
sseEmitter.send("错误 不能使用空提 示词运行代理");
sseEmitter.complete();
return;
}
} catch (IOException e) {
sseEmitter.completeWithError(e);
}
//切换执行状态
this.state = AgentState.RUNNING;
//记录上下文
messageList.add(new UserMessage(userPrompt));
//结果列表
List<String> results = new ArrayList<>();
try {
//执行循环
for (int i = 0; i < maxSteps && state != AgentState.FINISHED; i++) {
int stepNumber = i + 1;
currentStep = stepNumber;
log.info("Executing step {} and max {}", stepNumber, maxSteps);
//单步执行
String stepResult = step();
String result = "Step " + stepNumber + ": result: " + stepResult;
results.add(result);
//输出当前每一步的结果到sse
sseEmitter.send(result);
}
//检察是否超出限制
if (currentStep >= maxSteps) {
state = AgentState.FINISHED;
results.add("Terminated Reached max steps: " + maxSteps);
//输出当前每一步的结果到sse
sseEmitter.send("执行结束: 达到最大步骤: " + maxSteps);
}
//正常完成
sseEmitter.complete();
} catch (Exception e) {
state = AgentState.ERROR;
log.error("error executing agent", e);
try {
sseEmitter.send("执行错误: " + e.getMessage());
sseEmitter.complete();
} catch (IOException ex) {
sseEmitter.completeWithError(ex);
}
} finally {
//清理资源
this.cleanUp();
}
});
//设置超时时间 并且清理资源
sseEmitter.onTimeout(() -> {
this.state = AgentState.ERROR;
this.cleanUp();
log.warn("sse connection timeout");
});
sseEmitter.onCompletion(() -> {
if (this.state == AgentState.RUNNING) {
this.state = AgentState.FINISHED;
}
this.cleanUp();
log.warn("sse connection completed");
});
return sseEmitter;
}
前端
使用cursor 快速开发一个门户页面 并且测试问答